
Como aumentar as chances de sucesso de uma transição de carreira para gestão de produto?
6 de abril, 2024
Usando mentalidade de produto em serviços, ou seria o contrário?
21 de abril, 2024Como podemos andar mais rápido? Como podemos entregar mais com o mesmo time? Por que temos a impressão de que o time está lento? Quando o time era menor, parecia que ele conseguia entregar mais. Esses são questionamentos e afirmações muito comuns que ouço sobre times de desenvolvimento de produto. Toda empresa que tem um time de desenvolvimento de produtos digitais gostaria que esse time fosse mais rápido. Por esse motivo, vou mostrar como medimos e gerenciamos produtividade nos diferentes times que liderei.
No meu último ano na Locaweb, estávamos nos focando bastante em produtividade, em como os times de desenvolvimento de produto e de software da Locaweb poderiam produzir mais, sem precisarmos colocar mais gente nos times e sem que a qualidade das entregas caísse. O gráfico a seguir mostra nossos números. Contabilizamos quantidades de entregas por semana e, como dá para ver, em algumas semanas mais do que quadruplicamos a quantidade de entregas por semana:
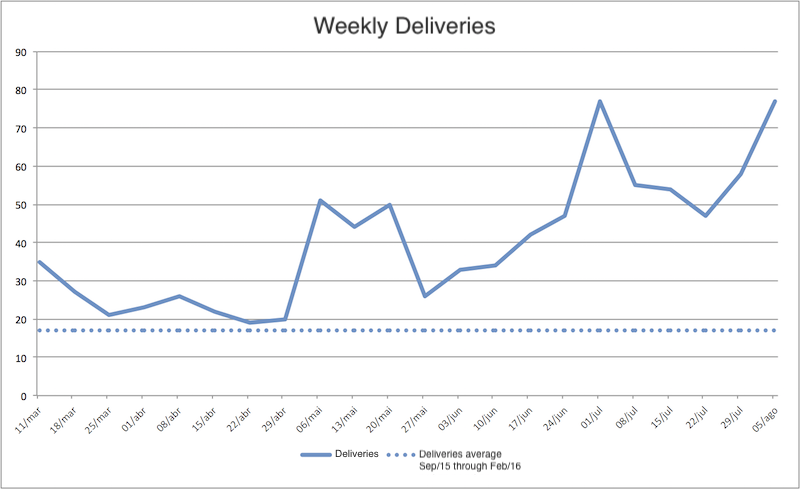 Entregas por semana na Locaweb.
Entregas por semana na Locaweb.
Esse aumento de produtividade aconteceu quando o time cresceu apenas 10% em quantidade de pessoas, logo, não dá para creditar esse aumento de produtividade ao aumento de pessoas nos times.
Quando há um aumento desses, além do natural questionamento sobre se o aumento de produtividade se deve ao aumento de pessoas nos times, outro questionamento que existe é se houve queda da qualidade das entregas. Uma das medições de qualidade que fazemos é a quantidade de rollbacks. Como é possível perceber a seguir, mesmo com o aumento de produtividade, a quantidade de rollbacks foi reduzida em 40%!
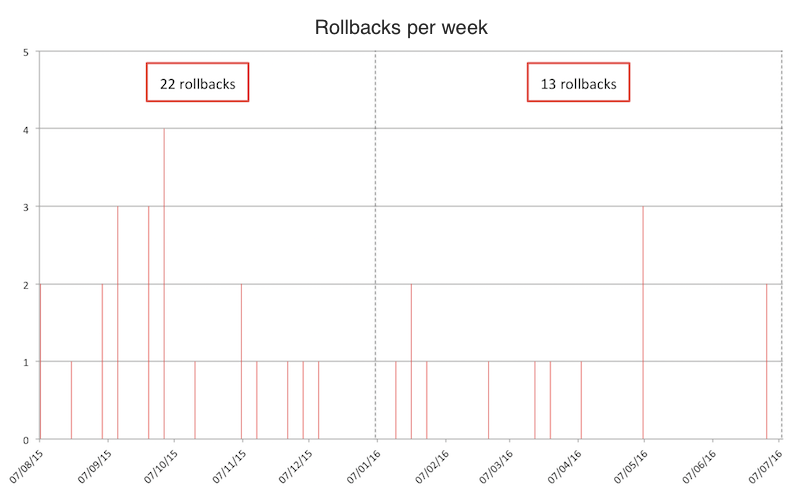 Rollbacks por semana na Locaweb.
Rollbacks por semana na Locaweb.
Depois que cheguei à Conta Azul, decidimos implementar o mesmo tipo de controle de entregas semanais e acabamos conseguindo também um bom aumento da produtividade.
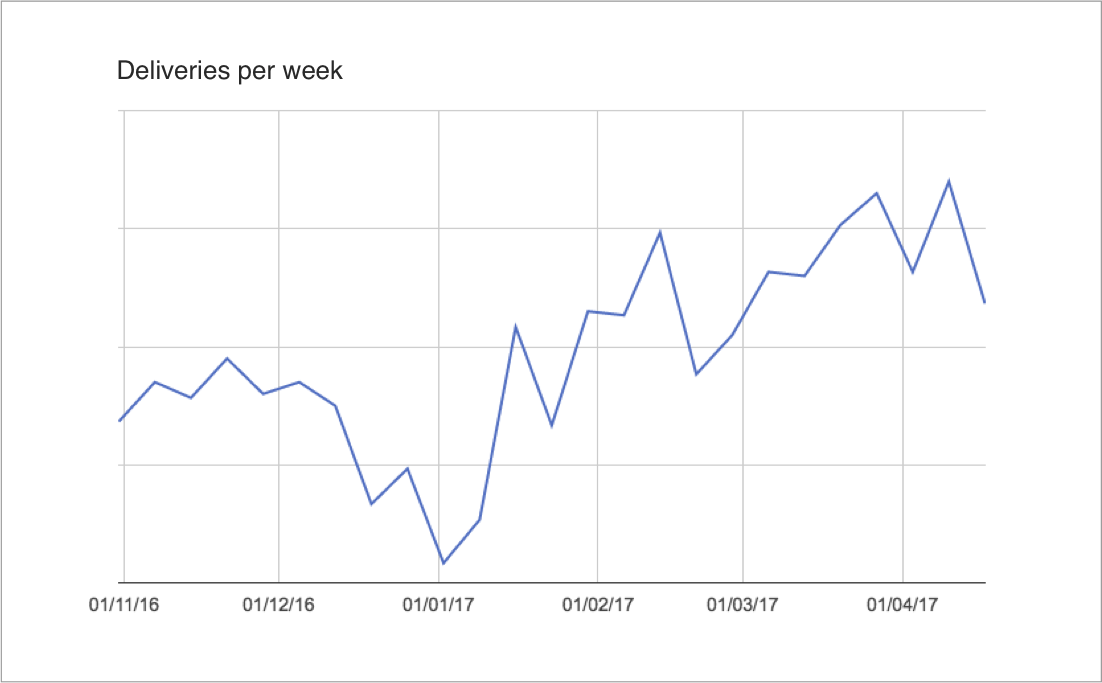 Entregas por semana na Conta Azul.
Entregas por semana na Conta Azul.
No Gympass, como estávamos crescendo a equipe muito rapidamente, decidimos controlar o número de entregas por pessoa por semana. Contamos as pessoas que ingressaram 2 meses antes, uma vez que as pessoas precisam de 1 a 2 meses para se tornarem produtivas. Em um trimestre, conseguimos aumentar em 16% nossa produtividade por pessoa.
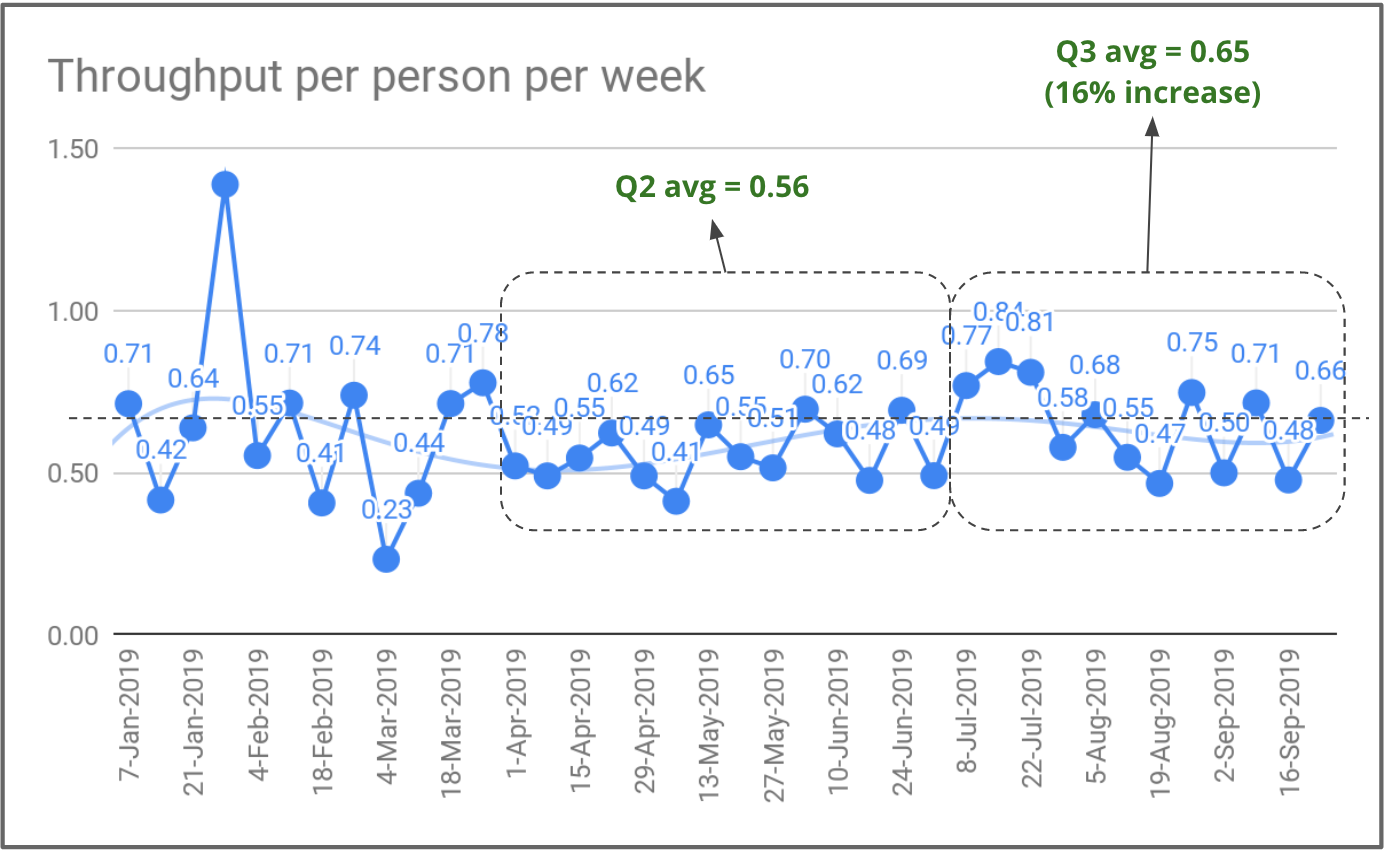 Entregas por pessoa por semana no Gympass.
Entregas por pessoa por semana no Gympass.
No Gympass, também medíamos o número de deploys, tanto em nosso core, conhecido como monólito, quanto em microsserviços. Também conseguimos um aumento considerável em um ano.
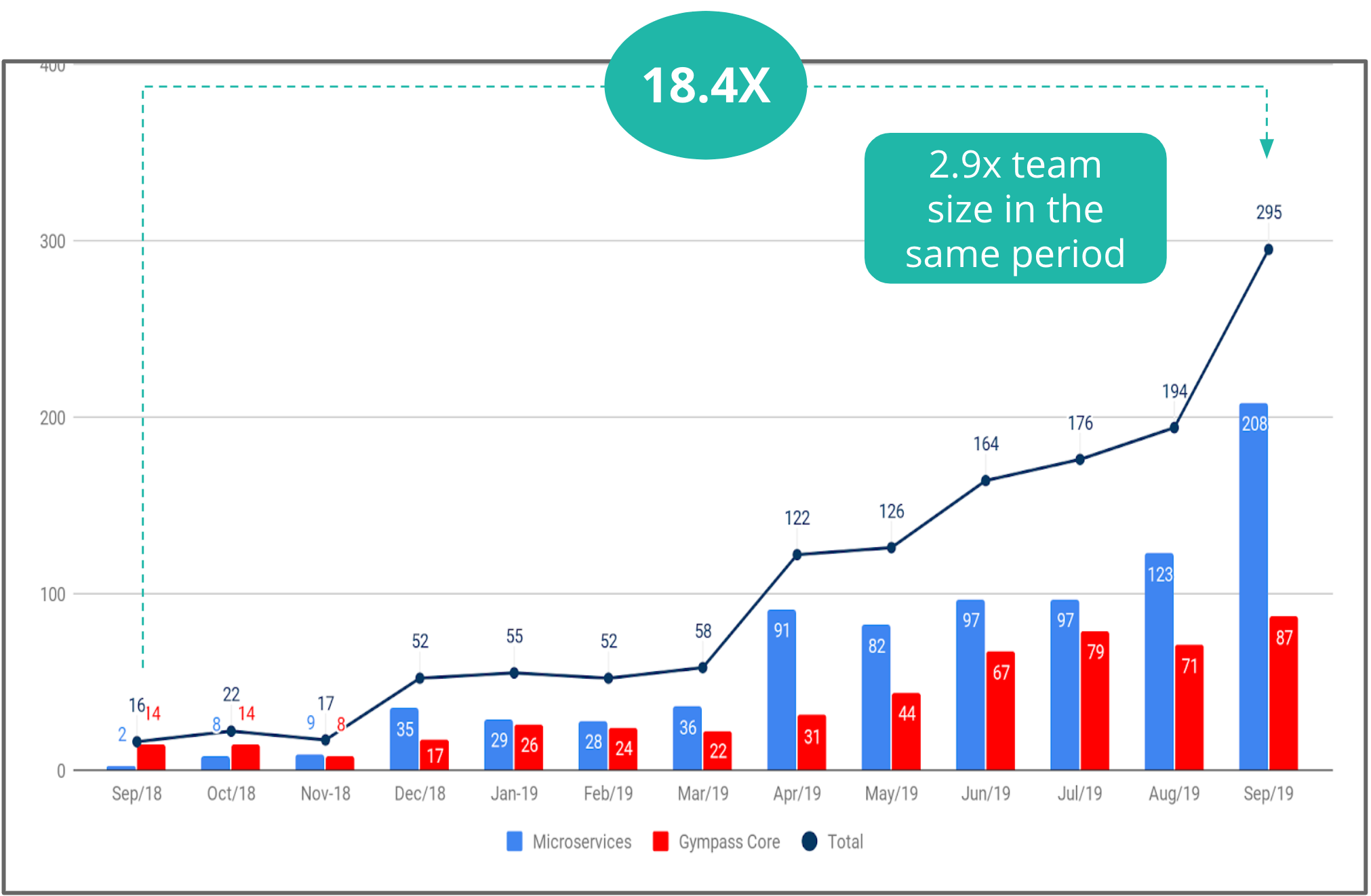 Entregas por mês no Gympass.
Entregas por mês no Gympass.
Na Lopes também conseguimos um aumento considerável. Assim que um deploy era feito, um e-mail era enviado com uma lista dos itens “deploiados”. Uma das primeiras coisas que fiz foi compilar esses relatórios em uma planilha para construir o gráfico adiante. Daí foi fácil notar que os deploys não aconteciam todos os dias. Aconteciam, em média, uma vez por semana. Assim que notamos isso, definimos OKRs para aumentar a frequência de deploys, o que vem surtindo efeito. Os OKRs que definimos foram:
- Objetivo: Aumentar a cadência de deploys em produção;
- KR: Aumentar o número de deploys por semana para no mínimo 3 (quanto mais, melhor);
- KR: Reduzir o número máximo de novas features por deploy para no máximo 10.
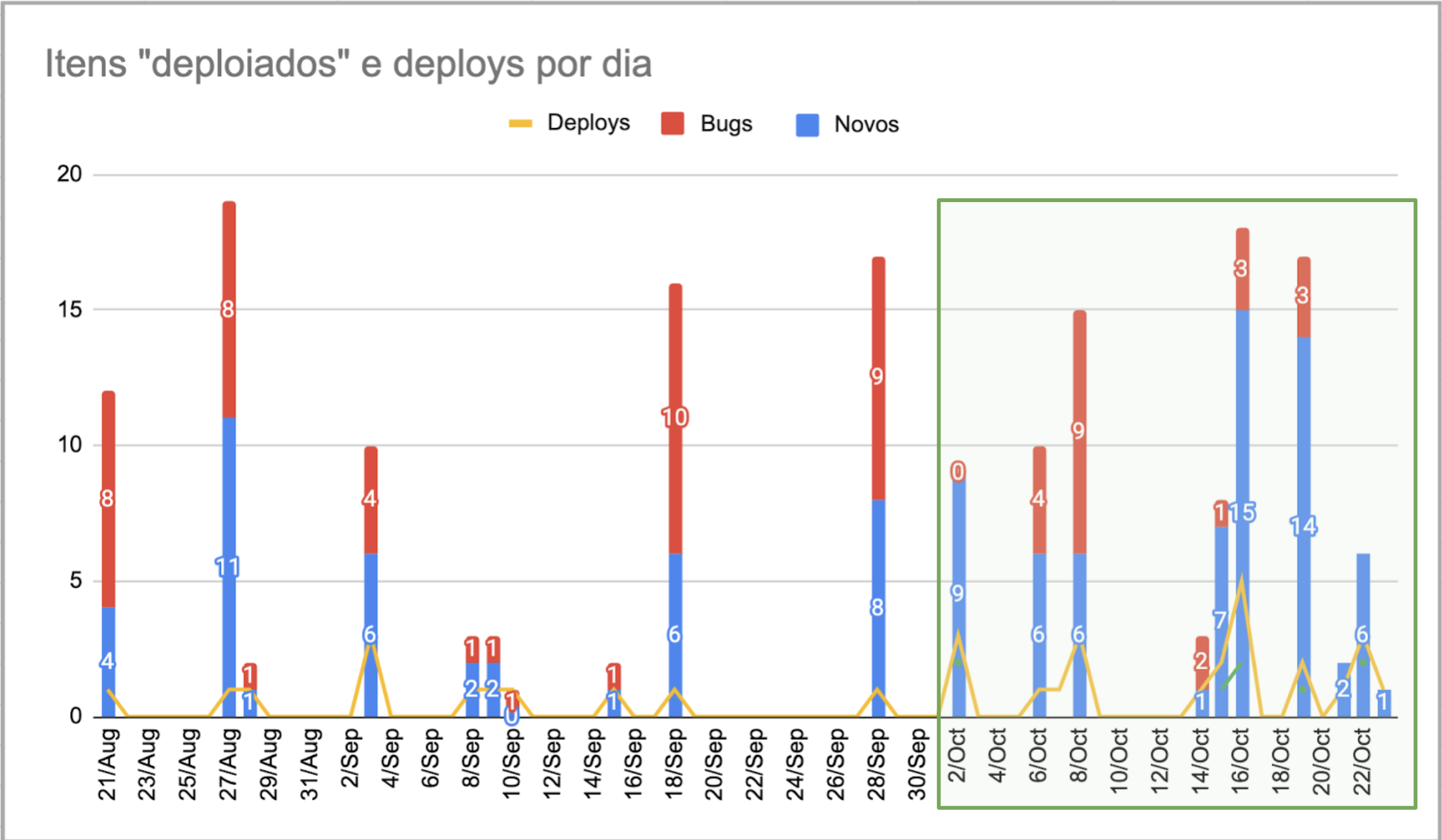 Deploys por dia na Lopes.
Deploys por dia na Lopes.
Comparando os dois períodos, temos:
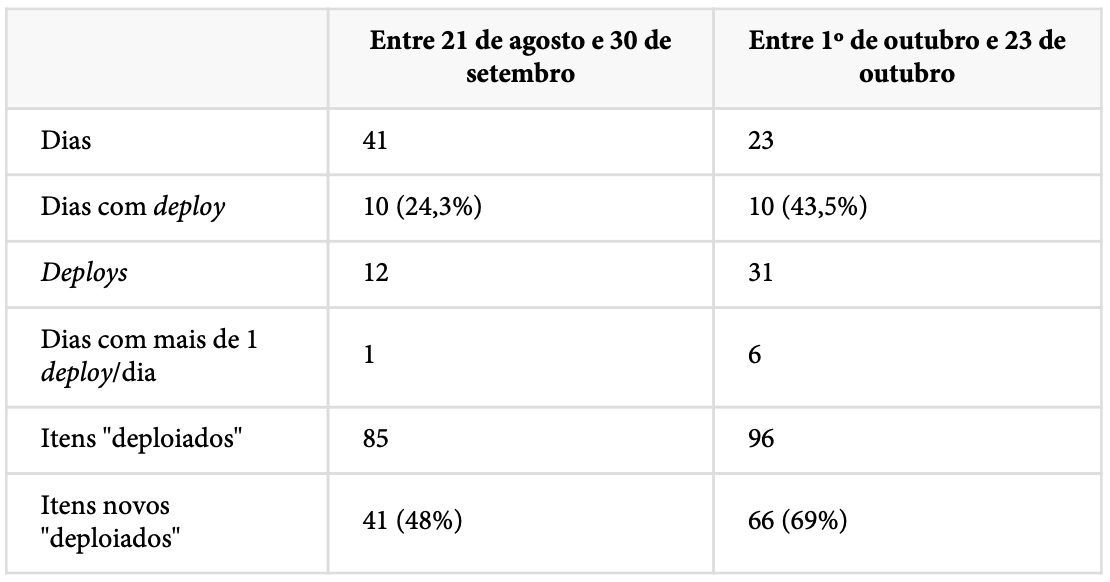
Como conseguimos isso?
Não há bala de prata: foram várias ações que tomamos, e temos certeza de que ainda há mais ações que poderão ser tomadas para aumentar ainda mais. Aqui vai uma lista do que fizemos na Locaweb para conseguir aumentar a produtividade do time de desenvolvimento de produto, práticas estas que depois levei para outras empresas.
Medir
Antes de mais nada, para melhorar qualquer coisa, é preciso medir para poder saber se essa coisa está melhorando! Fizemos uns cálculos estimados de entregas por semana no período de setembro de 2015 a fevereiro de 2016. O cálculo foi bem simples: total de deploys feitos no período dividido pelo número de semanas. Passamos, então, a comunicar toda a empresa sobre as entregas da semana.
Na Locaweb e na Conta Azul, cada gestor de produtos me mandava na sexta-feira as entregas da semana, eu compilava os dados e anotava a quantidade de cada semana, gerando esse gráfico. A partir do momento em que começamos a medir, ficou mais claro o nível em que estávamos, e as ações que passamos a fazer começaram a mostrar resultado no gráfico. Além disso, os times passaram a usar uma única ferramenta de medição, o Jira, o que deu a eles uma visão melhor de progresso de cada time e permitiu comparações com troca de experiência, isto é, algo na linha de “olha que interessante o seu gráfico, como vocês conseguiram aumentar esse indicador?”.
Kanban vs. sprint
Outro ponto que mexemos foi a mudança de Kanban para sprint. Antes, todos os times rodavam com Kanban. Só que, no Kanban, quando um item tem um impedimento, ele não pode ser mexido, e o time não pode fazer mais nada, ficando travado. No entanto, às vezes acontecia de o time mover um item de “doing” para “to be done”, por estar impedido, e pegar outro item para fazer, o que não deveria ser feito. Uma vez em “doing”, a tarefa só pode ir para “done”, não pode voltar para “to be done”, pois o controle da produtividade é perdido.
Com sprint, o time organiza as próximas duas semanas de trabalho, colocando vários itens para serem trabalhados. Assim, se algum item tiver impedimento, o time pode começar a mexer em outro item e, com isso, consegue entregar mais no mesmo intervalo de tempo.
Importante reforçar que isso não é uma crítica ao Kanban. Isso aconteceu em 2015. Acredito que não tínhamos maturidade e conhecimento suficiente para obter o melhor do Kanban, por isso optamos por mudar para o Scrum.
Discovery e delivery
O que a designer de UX e o gestor de produtos fazem pode ser chamado de discovery, que significa descobrir o que é preciso ser feito. Já o que a engenharia faz pode ser chamado de delivery, que é fazer e entregar o que tem de ser feito. Essa separação de papéis parece óbvia, mas não deixar isso explícito nos times pode atrapalhar o processo de desenvolvimento de software. Por quê? Existem alguns motivos.
O primeiro é que, se o discovery não é visto de forma explícita, não é claro o que é feito nessa fase e nem o que motiva certas decisões sobre o que deve ser implementado no software. É difícil fazer alguma coisa sem saber por que se está fazendo aquilo. O segundo motivo é que, quando essa separação não é explícita, itens podem ir e voltar de delivery para discovery, e vice-versa, sem critério. Não raro víamos nos times algo sendo implementado pelos engenheiros. E quando o pessoal de UX e o gestor de produtos viam sua especificação implementada, desejavam mudar algo, no meio do desenvolvimento. Com a separação clara entre discovery e delivery, definimos que, uma vez indo para delivery, não se mexe mais. Se quiser mexer de novo, deve passar por um novo discovery, para só então ir para delivery.
Tamanho das entregas
Em alguns casos, nossas entregas eram bem grandes, trabalho de várias semanas ou até alguns meses. Como já foi amplamente discutido em metodologias ágeis, a entrega frequente de software funcionando é um dos princípios da agilidade, reforçado pela técnica de entrega contínua. É só procurar no Google para encontrar inúmeros exemplos de empresas de primeira linha que fazem múltiplos deploys por dia, com algumas fazendo centenas deles! :-O
Para fazer isso, é preciso que os deploys sejam de entregas pequenas, bem pequenas. É preciso dividir toda história grande em histórias menores. Isso é trabalho do gestor de produtos em conjunto com o designer de UX. Já me perguntaram se isso não é trapacear, afinal, em vez de entregar uma história grande, entregaremos a mesma coisa, só que dividida em pequenas histórias. Parece ser a mesma coisa, mas, em vez de entregar algo grande depois de semanas, ou até mesmo meses, acabamos entregando valor todo dia, e assim nosso usuário já pode usufruir dos benefícios em vez de esperar semanas ou meses.
Além disso, ao colocar em produção todos os dias, já podemos aprender com o feedback e ajustar entregas futuras. E ainda há um benefício adicional: o fato de colocar em produção todo dia algum código faz desse processo de colocar código em produção algo mais simples, exatamente pelo fato de ser feito diariamente. Então, entregar uma história grande em um período de semanas ou meses não é a mesma coisa que quebrar essa história em pequenos pedaços e entregar um pedacinho todos os dias. Há ganhos claros de produtividade em se entregar pequenos pedaços com frequência.
Outro benefício adicional é que, ao facilitar para os engenheiros as ações de implantar (e reverter) código, isso ajudará a colocar o código na produção mais rapidamente.
Quando eu saí da Locaweb, estávamos começando a experimentar mais alguns pontos que tinham bom potencial para ter impacto na produtividade — é o que veremos nos próximos dois tópicos.
Primeira solução vs. solução mais simples
É da natureza humana querer resolver problemas. Assim que um problema aparece, a primeira reação é pensar em uma solução e sair implementando-a para resolvê-lo. Só que nem sempre a primeira solução é a melhor, tanto do ponto de vista do cliente quanto do ponto de vista de quem implementa a solução.
Por esse motivo, temos preferido não começar a resolver imediatamente cada novo problema que aparece. Buscamos antes verificar se há mais soluções possíveis, analisamos todas as soluções e só aí escolhemos uma solução para partirmos para a ação. Investir mais tempo pensando em outras possíveis soluções, sempre tendo claro qual a questão a ser resolvida e por que precisamos resolvê-la, ajuda a encontrar soluções simples. Uma solução simples (1 semana de implementação) que resolve 70% a 80% do problema é melhor do que uma complicada (1 mês de implementação) que resolve 100%. Na maioria das vezes, resolver 70% a 80% do problema é mais do que suficiente. Às vezes, a solução mais simples é não fazer nada!
Exemplificando, na Locaweb, o serviço de hospedagem e de e- mail pode deixar de funcionar por um motivo externo ao serviço. O domínio ao qual a hospedagem e o e-mail estão ligados, que é pago anualmente para o Registro.br, pode não ter sido renovado e, quando ele não é renovado, os serviços associados a esse domínio deixam de funcionar, mesmo que tudo esteja operando perfeitamente na Locaweb. Recentemente, a Registro.br disponibilizou uma forma de a Locaweb cobrar o domínio do cliente em nome da Registro.br. A princípio, a ideia parece boa, pois, ao cobrarmos, garantimos que o cliente sabe que tem de pagar esse domínio para manter os serviços no ar. Só que, analisando um pouco melhor, vimos que essa solução pode gerar mais problemas.
O cliente receberá duas cobranças pela mesma coisa, o registro de domínio, pois o Registro.br continuaria a cobrá-lo. O que acontece se ele pagar as duas cobranças? E se ele pagar só a da Registro.br? E se ele pagar só a da Locaweb? Além disso, implementar um novo tipo de cobrança, na qual cobraríamos pelo serviço de terceiro, seria algo novo para o time e para a Locaweb. Novos processos teriam de ser desenhados. Começamos então a pensar se não existiriam formas mais simples de resolver o problema de ajudar nosso cliente a não esquecer que ele tem de pagar por seu registro de domínio na Registro.br.
Como para poder cobrar pela Registro.br é necessário acessar a informação de que o domínio está para expirar, pensamos na seguinte solução: vamos implementar uma régua de comunicação com esse cliente avisando-o da importância de pagar o Registro.br, para garantir que o serviço continue funcionando; é uma solução bem mais simples do que duplicar o processo de cobrança. Se a Registro.br fornecer também um link direto para a cobrança do domínio, podemos mandar esse link na comunicação. Assim, as chances de resolver o problema aumentam ainda mais, e uma régua de comunicação é bem mais simples de implementar do que uma cobrança duplicada.
Escolha da ferramenta mais apropriada
Aqui o tema são ferramentas para implementação da solução. Linguagem de programação, frameworks e bancos de dados. Cada ferramenta tem suas características e são mais apropriadas para resolver certos tipos de problemas. Escolher a ferramenta certa para cada problema vai impactar a produtividade. Esse é um tema que estamos começando a estudar agora.
Hoje usamos Rails para quase tudo, mas existem alguns problemas que podem ser mais simples e rápidos de se resolver com a implementação de uma solução usando outro framework ou linguagem. Usar uma única linguagem de programação para todos os problemas é como usar uma única ferramenta para todos os consertos que precisam ser feitos. Será que o martelo é a melhor ferramenta para apertar um parafuso? Será que Rails é a melhor ferramenta para gerenciar filas?
Temos confiança de que, com esses dois pontos que estamos começando a mexer agora, conseguiremos aumentar a produtividade por 10x ou mais! E com certeza há outros pontos que sequer percebemos ainda e que, quando os percebermos e tratarmos, terão impacto ainda maior.
O que impacta a produtividade
A produtividade de um time de desenvolvimento de produto é impactada por vários fatores. Certa vez, encontrei um artigo bem interessante escrito pelo time de desenvolvimento da Apptio (2019) no qual eles mostram um mapa mental com todos os elementos que podem impactar positiva ou negativamente a produtividade de um time de desenvolvimento de produto:
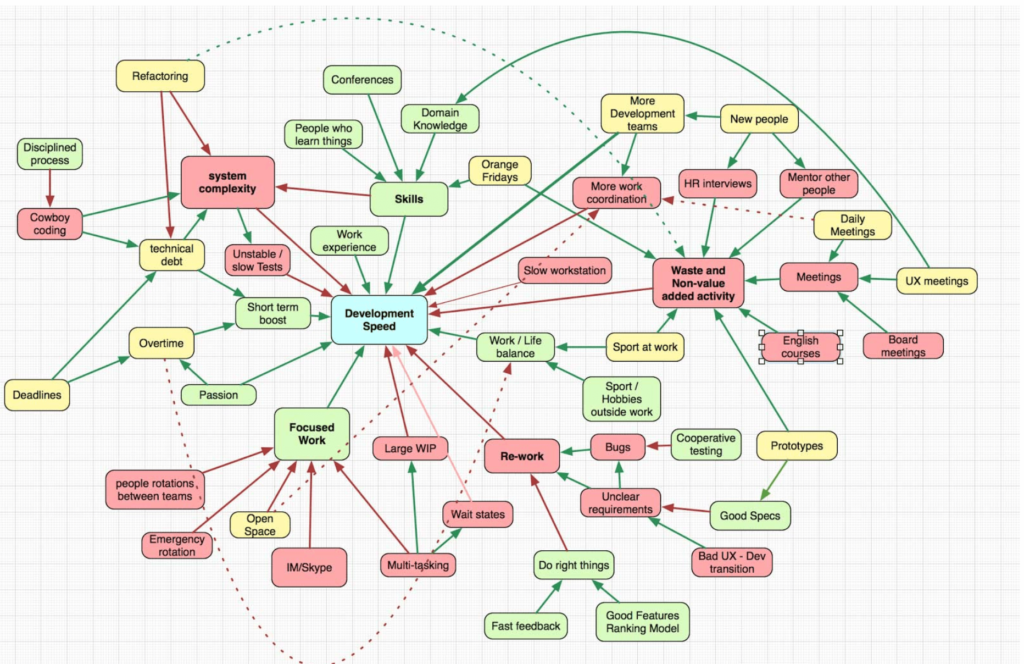 Mapa mental da Apptio sobre o que impacta a produtividade. Adaptado de: Apptio, 2019.
Mapa mental da Apptio sobre o que impacta a produtividade. Adaptado de: Apptio, 2019.
Esse diagrama mostra coisas e atividades que afetam a velocidade de desenvolvimento de alguma forma. Verde significa que uma atividade aumenta a velocidade. Quanto mais você tiver, melhor. Amarelo indica que existe algum máximo. Por exemplo, você pode acumular dívida técnica e aumentar a velocidade, mas, se acumular muito, isso o atrasará significativamente. O vermelho mostra coisas que retardam o desenvolvimento, e quanto menos você tiver, melhor. A seta verde indica efeito crescente. Por exemplo, o trabalho focado aumenta a velocidade de desenvolvimento. A seta vermelha indica efeito decrescente. Por exemplo, melhores habilidades de desenvolvimento diminuem a complexidade do sistema (bons engenheiros criam sistemas menos complexos).
O que gosto dessa imagem é que ela mostra quão complexo é esse tema e quantas coisas podem impactar positiva ou negativamente a velocidade do time. Na Conta Azul, acompanhávamos esse tema todo trimestre na Product Council, reunião em que conversávamos sobre o planejamento trimestral do time de desenvolvimento de produto com a liderança. Tinha um slide no qual elencávamos todos os temas que podiam impactar a velocidade para discutirmos o que estávamos fazendo sobre cada um desses tópicos. Veja:
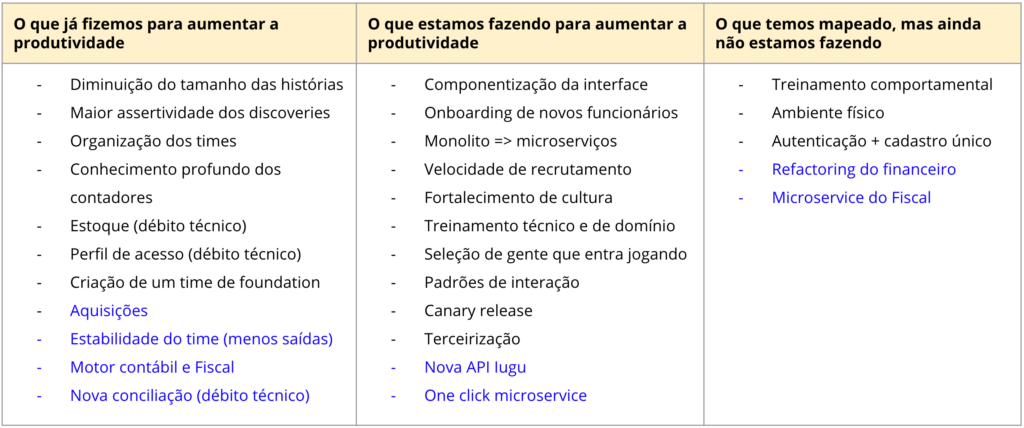 Temas que impactavam a velocidade do time de desenvolvimento de produto da Conta Azul.
Temas que impactavam a velocidade do time de desenvolvimento de produto da Conta Azul.
Coloque o tema produtividade no centro da discussão
Não há bala de prata: com cada time em que trabalhei, foram várias as ações que tomamos e sempre tivemos a certeza de que sempre há mais ações que poderão ser tomadas para aumentar a produtividade ainda mais. A única bala de prata que existe é transformarmos produtividade em tema importante de nossas conversas. Todos passaram a conversar sobre produtividade e sobre o que poderíamos fazer para melhorá-la.
Esse movimento nos fez iniciar várias mudanças e experimentos que nos ajudaram a aumentar consideravelmente nossa produtividade. Se você também quer aumentar a produtividade de seu time de desenvolvimento de produtos, coloque isso como tema central de suas conversas e experimente bastante. Você verá como há espaço para melhorar bastante a produtividade dos seus times de desenvolvimento de software.
Outro ponto importante: não deixe para discutir o tema produtividade esporadicamente. Minha recomendação é que você o faça semanalmente. Criar uma cadência semanal dará oportunidade de, a cada semana, experimentar com algo novo e discutir os resultados com o time.
E a qualidade?
Como comentei anteriormente, ao aumentarmos a quantidade de deploys feitos na Locaweb, nossa qualidade não caiu. Houve até uma melhora significativa de qualidade, uma vez que, após o aumento de produtividade, a quantidade de rollbacks foi reduzida em 40%. Isso acontece porque, com a frequência maior de deploys, o tamanho desses deploys diminui e, consequentemente, por serem itens menores, a chance de haver erros é menor.
Uma simples pesquisa no Google sobre qualidade de software produzirá toneladas de definições normalmente relacionadas ao atendimento de requisitos funcionais e não funcionais. Quando o software não atende a um requisito funcional ou não funcional, ele apresenta um defeito, um bug. Portanto, para melhorar a qualidade de um produto de software, precisamos trabalhar em duas coisas:
- Reduzir os bugs existentes;
- Não gerar novos bugs.
Uma boa maneira de controlar isso é ter uma medição semanal de seu inventário de bugs e novos bugs e discutir isso semanalmente com a equipe. Fizemos isso no Gympass. Definimos no início de cada trimestre qual é a meta para o inventário de bugs e a média de novos bugs por semana.
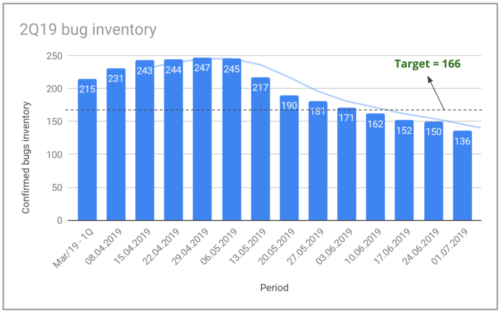 Quantidade total de bugs no Gympass.
Quantidade total de bugs no Gympass.
A imagem mostra a evolução do nosso estoque de bugs para o 2o trimestre de 2019. Iniciamos o trimestre com 215 bugs em nosso estoque e almejamos uma meta de menos de 166 ao final do trimestre, uma redução de quase 23%. Fechamos o trimestre com um estoque de 136 bugs, uma redução de 36%. Fizemos isso nos concentrando não apenas na resolução de bugs em nosso inventário, mas também no controle do número de novos bugs por semana.
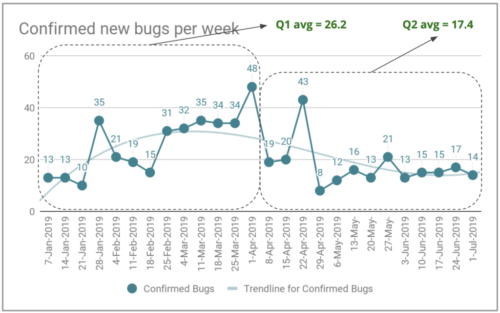 Quantidade de novos bugs detectados por semana no Gympass.
Quantidade de novos bugs detectados por semana no Gympass.
No primeiro trimestre de 2019, tivemos uma média de 26,2 bugs criados por semana. Durante o segundo trimestre, reduzimos essa média para 17,4 novos bugs por semana, para um total de 226 novos bugs durante o trimestre. Isso é uma redução de 33% no número de novos bugs por semana. Isso parece uma melhoria muito boa, certo? Mas há muito espaço para melhorias aí. Deixe- me explicar a matemática do gerenciamento de bugs.
Se fomos capazes de reduzir nosso estoque de bugs de 215 para 136, isso significa que resolvemos pelo menos 79 bugs. No entanto, criamos 226 novos bugs (17,4 novos bugs por semana x 13 semanas) durante o trimestre. Resolvemos 79 + 226 = 305 bugs durante o trimestre; é muito trabalho de correção de bugs. Se tivéssemos gerado 90 novos bugs durante o trimestre, uma média de 6,9 novos bugs por semana, em vez dos 226 novos bugs, poderíamos ter zerado o inventário de bugs.
Um aspecto adicional da resolução do bug a ser medido é o SLA (Service Level Agreement) de resolução, que é a quantidade de dias que a equipe leva para resolver um bug a partir do dia em que o bug foi identificado pela primeira vez. Para isso, classificamos os bugs pela sua gravidade, que é o impacto que causa aos usuários e ao negócio. Os bugs de maior gravidade são aqueles que precisamos resolver no mesmo dia; erros de alta gravidade, em 7 dias e de média gravidade, em 14 dias. O gráfico a seguir mostra como estávamos no Gympass no quarto trimestre de 2019:
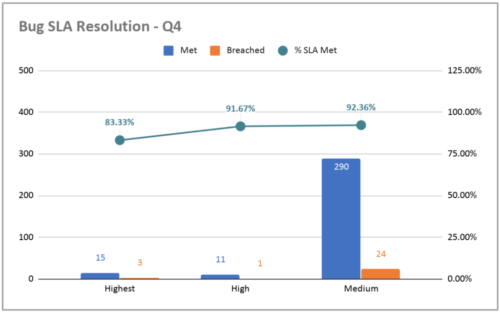 SLA de resolução de bugs no Gympass.
SLA de resolução de bugs no Gympass.
No entanto, essa não é a visualização ideal porque mostra apenas uma imagem do momento, não uma evolução. Para entender a evolução de qualquer métrica, você precisa ver como ela se saiu em diferentes pontos no tempo.
Assim que me juntei à Lopes, comecei a trazer esse tema para a discussão com os times. Uma das coisas que notamos é que 50% dos itens “deploiados” era correção de bugs. Fui informado de que “esses bugs eram pegos antes de ir para produção, o que é algo bom”. De fato, ainda bem que esses bugs não chegaram ao ambiente de produção e apareceram para nossos usuários. Entretanto, eles chegaram à pré-produção e precisavam ser corrigidos. Não seria melhor se esses erros sequer existissem, nem mesmo em pré-produção?
Os OKRs que definimos para nos ajudar com o tema qualidade foram 3 KRs adicionais no objetivo de Aumentar a cadência de deploys em produção que comentei anteriormente:
- KR: Reduzir o número de novos bugs para 5% em pré- produção;
- KR: Reduzir o número de bugs totais para 10% em pré- produção;
- KR: Manter o número de bugs totais abaixo de 5% em produção.
E adicionamos o seguinte OKR:
- Objetivo: Melhorar a qualidade das entregas dos squads;
- KR: Revisar 100% das novas histórias para encontrar requisitos mal definidos e/ou ambíguos;
- KR: Efetuar revisão de 25% dos pull requests dos squads;
- KR: Mensurar volume de pull requests dos squads.
Nos primeiros 23 dias rodando com esses OKRs no início de 4o trimestre de 2021, conseguimos reduzir de 52% para 31% dos itens “deploiados” para correção de bugs.
Outro exemplo de controle de bugs
Na Conta Azul, dobramos o time de desenvolvimento de produtos em um período de 8 meses entre novembro de 2017 e julho de 2018. Esse crescimento tinha por objetivo aumentar a capacidade produtiva do time.
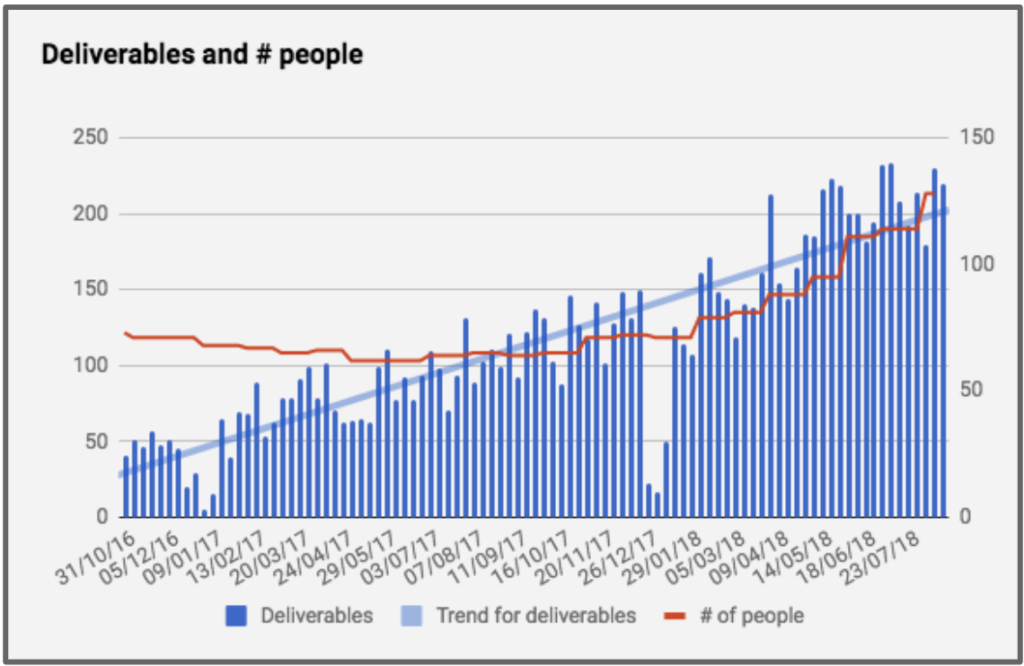 Quantidade de entregas e de pessoas por semana da Conta Azul.
Quantidade de entregas e de pessoas por semana da Conta Azul.
Além disso, dividimos a quantidade de entregas pelo total de pessoas no time para avaliar se estávamos conseguindo aumentar nossa produtividade individualmente.
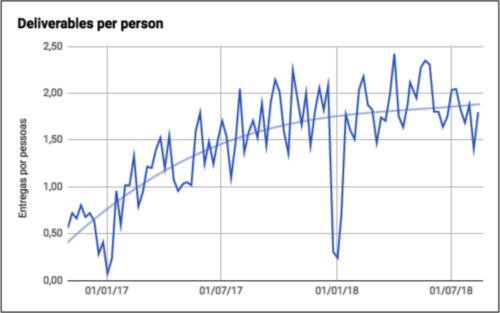 Entregas por pessoa por sem ana na Conta Azul.
Entregas por pessoa por sem ana na Conta Azul.
Com o aumento de pessoas no time, acabou aumentando a quantidade de bugs. O time que já vinha tendo 40% de suas entregas como correção de bugs acabou aumentando essa proporção para 60%. Ou seja, apesar de ter aumentado a produtividade individual e total, esse aumento de produtividade não estava sendo sentido pelo usuário, pois acabava sendo usado para refação.
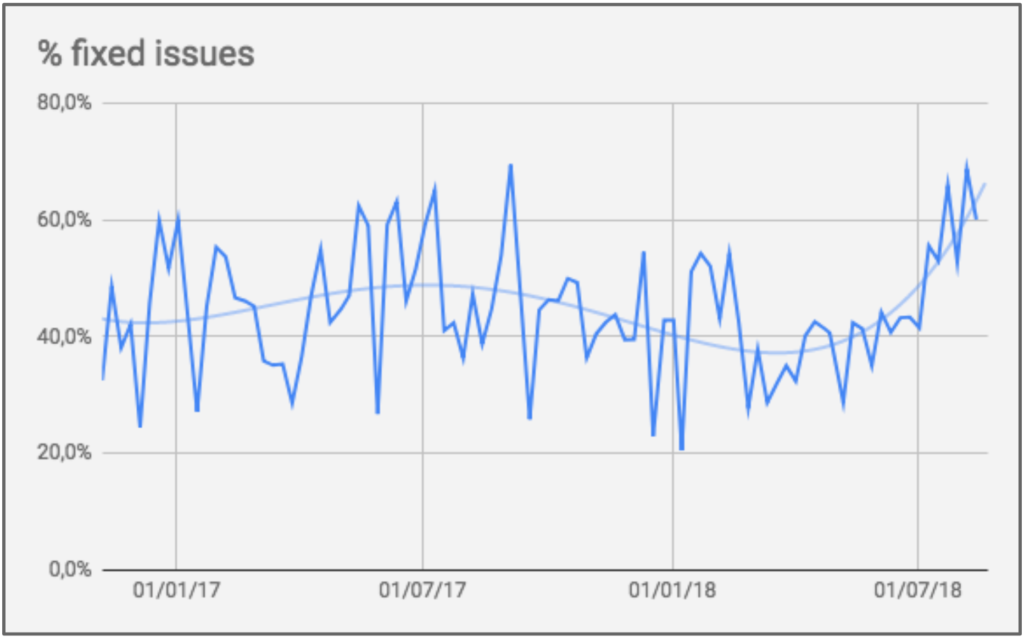 Percentual de correção de bug na Conta Azul.
Percentual de correção de bug na Conta Azul.
Para controlarmos esse problema, aumentamos nosso foco em corrigir esses bugs dentro dos SLAs, que eram:
- 85% dos chamados resolvidos em até 7 dias;
- 98% dos chamados resolvidos em até 30 dias.
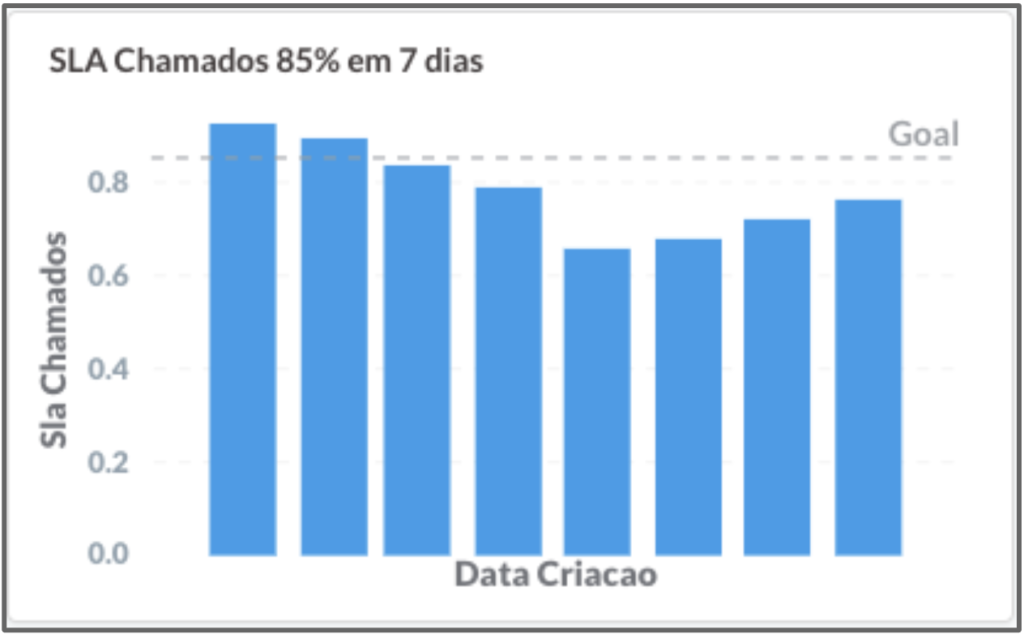 SLA de resolução de bugs em 7 dias da Conta Azul.
SLA de resolução de bugs em 7 dias da Conta Azul.
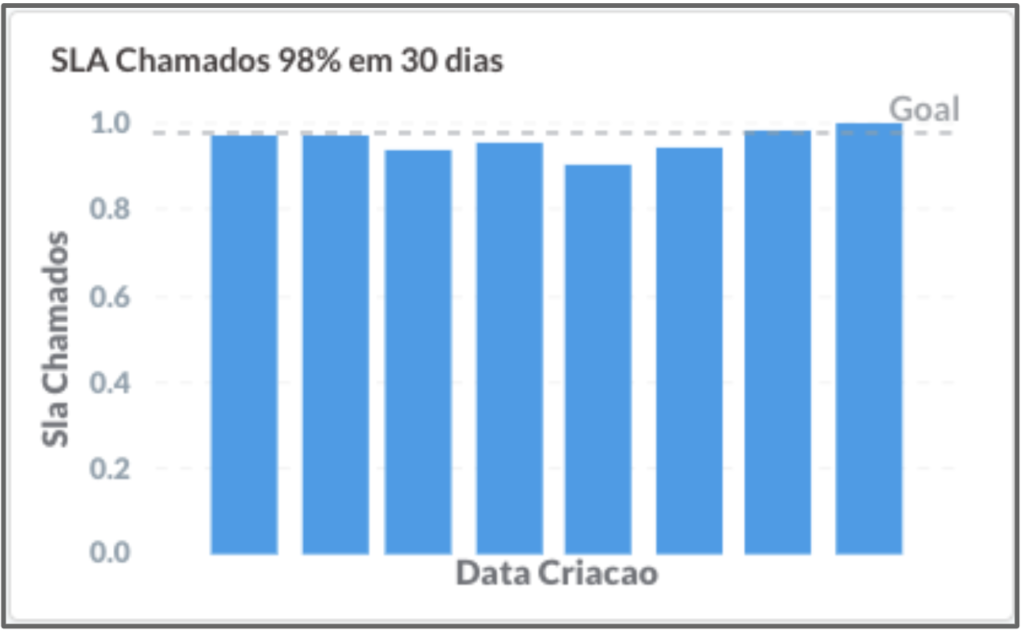 SLA de resolução de bugs em 30 dias da Conta Azul.
SLA de resolução de bugs em 30 dias da Conta Azul.
Veja que a qualidade piorou e o cliente sofreu com isso. Mas, depois de algum tempo, conseguimos retornar aos níveis de SLA definidos. Olhávamos essa métrica semanalmente e, sempre quando discutíamos sobre ela, concordávamos que a melhor maneira de cumprir o SLA era não criar bugs!
Qualidade não é só controle de bugs
Além do controle de bugs, há vários outros aspectos que impactam na qualidade do produto digital que entregamos para os usuários. Desempenho, escalabilidade, operabilidade e monitorabilidade são alguns exemplos de requisitos não funcionais.
Quando me juntei ao Gympass, na minha segunda segunda- feira o sistema ficou fora para os usuários por volta das 19h. Comecei a perguntar para as pessoas do time o que estava acontecendo, e a resposta foi que as segundas-feiras são dias de pico de visita às academias e que às vezes o sistema não dava conta do volume. Como não havia monitoração, não éramos alertados de que o volume estava maior do que o usual e não conseguíamos nos preparar adequadamente. Dois meses depois, quando o Rodrigo Rodrigues se juntou ao Gympass como CTO, ele apelidou o evento de “Black Mondays”, em função do alto volume de acessos que acontecia às segundas-feiras, similar ao alto volume de acessos que os sites de e-commerce recebem nas Black Fridays. Para endereçar o problema, passamos a monitorar e implementar uma infraestrutura que desse conta dos picos das segundas-feiras. E definimos OKRs para uptime, requests de HTTP bem-sucedidos e tempo de resposta do back-end.
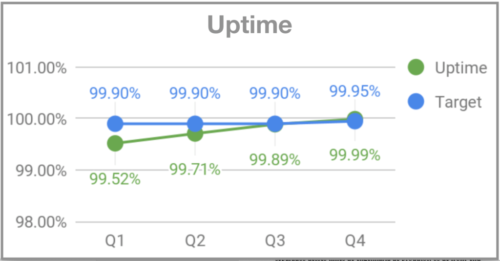 Uptime – Gympass.
Uptime – Gympass.
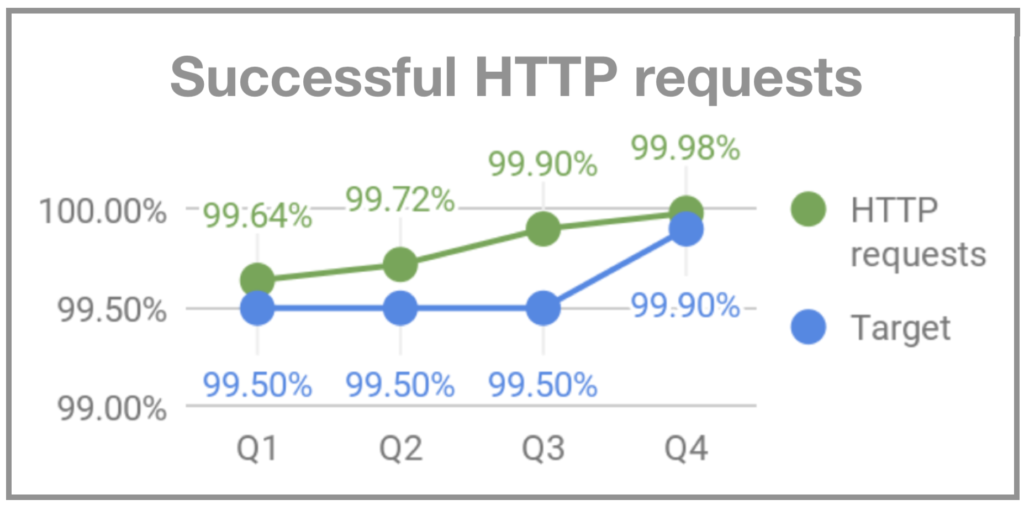 Requests de HTTP bem-sucedidos – Gympass.
Requests de HTTP bem-sucedidos – Gympass.
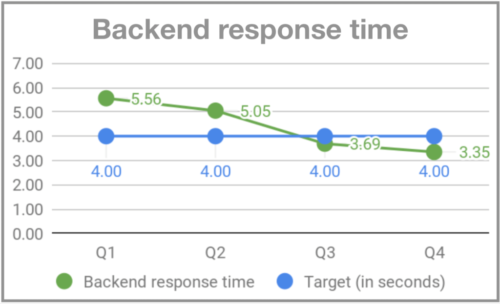 Tempos de resposta do back-end – Gympass.
Tempos de resposta do back-end – Gympass.
Por que a qualidade é tão importante?
Qualquer usuário prefere utilizar um produto de boa qualidade que se comporte conforme o esperado. Isso é condição sine qua non para fornecer uma boa experiência do usuário.
Além da experiência do usuário, há outro aspecto importante a considerar quando falamos sobre qualidade e bugs. Sempre que alguém precisa trabalhar na resolução de um bug que foi encontrado em um produto digital, essa pessoa precisa parar de trabalhar no que quer que esteja trabalhando no momento para poder resolver o bug. Esta é uma interrupção no fluxo de trabalho. Se essa pessoa fosse capaz de entregar o software sem aquele bug, ela poderia continuar a trabalhar em coisas novas sem interrupções, o que a tornaria mais produtiva.
A relação entre produtividade e qualidade
Tive a oportunidade de participar de um curso do MIT sobre como criar organizações de alta velocidade. O curso foi ministrado pelo professor Steven J. Spear, autor do livro The High-Velocity Edge: How Market Leaders Leverage Operational Excellence to Beat the Competition, e é um daqueles cursos muito densos, cheios de conteúdo, mas que pode ser resumido em um parágrafo:
Organizações de alta velocidade são capazes de aprender muito rápido, especialmente com suas falhas, e de absorver esse aprendizado como parte integrante do conhecimento da organização.
Uma organização de alta velocidade trabalha seguindo 4 passos:
- Estar preparada para capturar conhecimento e encontrar problemas em sua operação;
- Entender e resolver esses problemas para construir novos conhecimentos;
- Compartilharonovoconhecimentocomtodaaorganização;
- Liderar para desenvolver as habilidades 1, 2 e 3.
O exemplo clássico é a Toyota, com a manufatura enxuta e o conceito de parar a produção sempre que houver falhas, corrigindo-as e usando-as como oportunidade de aprendizado para que não aconteçam mais. Essa capacidade de aprender com as falhas é o que dá à Toyota a capacidade de permanecer à frente de seus concorrentes por tanto tempo.
Outro bom exemplo é a Alcoa, que tinha uma taxa de incidentes de trabalho de 2% ao ano, considerada normal. A Alcoa tem mais de 40 mil funcionários, portanto, 2% de incidentes de trabalho por ano significa que cerca de 800 funcionários por ano têm algum tipo de incidente de trabalho. Esse é um número bastante impressionante e preocupante.
Para combater esse problema, eles implementaram uma política de tolerância zero a erros. Antes de implementar essa política, os erros eram vistos como parte do trabalho. Agora, os funcionários são incentivados a relatar erros de operação em 24 horas, propor soluções em 48 horas e contar a solução encontrada para seus colegas para garantir que o conhecimento se espalhe por toda a organização.
Isso fez com que o risco de incidentes caísse de 2% para 0,07% ao ano! Essa redução na taxa de incidentes significava que menos de 30 funcionários por ano tinham algum problema de incidente de trabalho depois que a política de tolerância zero a erros foi implementada, e a Alcoa obteve um aumento de produtividade e qualidade semelhante ao da Toyota.
Falhar rápido vs. aprender rápido
Um fator importante nos exemplos da Toyota e da Alcoa é que reconhecer e aprender com as falhas deve fazer parte da cultura da empresa. Isso é algo um pouco mais comum na cultura das empresas de tecnologia, mas não tão comum em empresas tradicionais.
Durante o curso que fiz no MIT, dividi mesa com um executivo brasileiro do Grupo Globo, um executivo espanhol da AMC Networks International (produtora de séries como The Walking Dead, Breaking Bad e Mad Men), um gerente de projetos alemão, residente no Azerbaijão, que trabalha para a Swire Pacific Offshore (indústria de petróleo e gás) e com uma estudante vinda da Arábia Saudita que fazia seu pós-doutorado no MIT em energia solar. Todos os meus companheiros de mesa eram de indústrias mais tradicionais, eu era o único de uma empresa de tecnologia (eu estava na Conta Azul nessa época). Os executivos da Globo e da AMC estavam lá porque viram a Netflix, com seu streaming de vídeo sob demanda, e o YouTube, com seu enorme catálogo de vídeos gerados por usuários, como grandes ameaças, roubando seu público muito rapidamente, e eles queriam entender como poderiam se defender — embora o tema seja um tanto óbvio para as empresas de tecnologia, especialmente com a cultura que valoriza o fail fast (falhar rápido). É isso que torna a Netflix e o YouTube uma ameaça às empresas de mídia tradicionais, como o Grupo Globo e AMC Networks.
No entanto, mesmo isso sendo parte da cultura das empresas de tecnologia, sentar e discutir isso com pessoas de empresas mais tradicionais foi uma grande oportunidade de reflexão sobre a relação entre a falha, o reconhecimento da falha, o aprendizado e a alta velocidade:
- Reconhecer as falhas e usá-las como uma oportunidade de aprendizagem deve estar bem enraizado na cultura da organização. Se as pessoas não tomarem cuidado, à medida que uma empresa cresce, ela pode perder a capacidade de aceitar as falhas como oportunidades de aprendizado. É muito comum que as empresas, à medida que cresçam, sejam cada vez mais avessas a falhas e criem uma cultura que, em última análise, incentive as pessoas a esconderem erros e falhas.
- Outro aspecto importante do aprendizado com as falhas é tornar esse processo um padrão da empresa. Não adianta falhar, reconhecer o erro, afirmar que você não vai mais cometer aquela falha e, algum tempo depois, cometê-la novamente. Esse processo de aprendizado com as falhas deve fazer parte da cultura da empresa. Sempre que uma falha é identificada, o aprendizado deve acontecer o mais rápido possível para evitar que ela aconteça novamente. Se a mesma falha acontecer novamente, algo está quebrado no processo de aprendizagem com a falha.
- Mesmo em empresas de tecnologia, percebo que aprender com as falhas é mais comum na equipe de desenvolvimento de produtos, uma vez que retrospectivas e aprendizado contínuo fazem parte da cultura de desenvolvimento ágil de software. Em outras áreas da empresa, aprender com as falhas é menos comum. Essa capacidade de sistematizar o aprendizado com o fracasso deve permear toda a empresa.
Mesmo que ouçamos muito sobre a cultura das empresas de internet de falhar rápido, falar sobre falhar rápido diverge nosso foco do que é realmente importante: aprender rápido. Devemos colocar nossa energia no aprendizado, não no fracasso. É o processo de aprendizagem que faz evoluir pessoas e empresas. E é a capacidade de uma organização aprender rápido, principalmente com seus fracassos, que vai permitir que ela se mova em velocidades realmente altas.
Transformação digital e cultura de produto
Esse artigo é mais um trecho do meu mais novo livro “Transformação digital e cultura de produto: Como colocar a tecnologia no centro da estratégia da sua empresa“, que vou também disponibilizar aqui no blog. Até o momento, já publiquei aqui:
- Sobre o livro
- Parte 1: Conceitos
- Capítulo 1: A tal da transformação digital – Projeto e Produto
- Capítulo 2: Incerteza e transformação digital
- Capítulo 3: Tipo de empresa
- Capítulo 4: Tipo de empresa x maturidade digital
- Capítulo 5: Modelos de negócio
- Capítulo 6: Cultura ágil, digital e de produto
- Parte 2: Princípios
- Capítulo 7: Entregas rápidas e frequentes
Treinamento e consultoria em gestão de produtos e transformação digital
Ajudo líderes de produto (CPOs, heads de produtos, CTOs, CEOs, tech founders, heads de transformação digital) a enfrentarem seus desafios e oportunidades de produtos digitais por meio de treinamentos e consultoria em gestão de produtos e transformação digital.
Gestão de produtos digitais
Você trabalha com produtos digitais? Quer saber mais sobre como gerenciar um produto digital para aumentar suas chances de sucesso, resolver os problemas do usuário e atingir os objetivos da empresa? Confira meu pacote de gerenciamento de produto digital com meus 4 livros, onde compartilho o que aprendi durante meus mais de 30 anos de experiência na criação e gerenciamento de produtos digitais. Se preferir, pode comprar os livros individualmente:
- Transformação digital e cultura de produto: Como colocar a tecnologia no centro da estratégia de sua empresa
- Liderança de produtos digitais: A ciência e a arte da gestão de times de produto.
- Gestão de produtos: Como aumentar as chances de sucesso do seu software.
- Guia da Startup: Como startups e empresas estabelecidas podem criar produtos de software rentáveis.
