Medindo e gerenciando a produtividade
15 de junho, 2021Relacionamentos
8 de julho, 2021Em 2015, decidimos extinguir a função de Quality Assurance (QA) de nossa equipe de desenvolvimento de produtos da Locaweb. Tínhamos 12 QAs, alguns com perfil de desenvolvedor e outros com perfil SysAdmin. Ao propor a extinção da função de QA, alguns dos QAs se tornaram devs, enquanto outros assumiram a função de administradores de sistemas. Os motivos que nos levaram a extinguir a função de QA da Locaweb são:
- Quando existe uma função de QA separada da função de desenvolvimento de software, é comum ouvir frases como “a funcionalidade está pronta, agora está em fase de QA”, o que denota uma cultura de desenvolvimento de produto em cascata. Essa cultura pode aumentar consideravelmente o tempo de desenvolvimento e afetar negativamente a qualidade do software.
- Quando há uma função de QA separada da função de desenvolvimento de software, também é comum ouvir frases como “por que o QA não detectou esse bug?”, o que denota uma cultura de encontrar os culpados. Essa cultura pode ser muito prejudicial ao engajamento e motivação da equipe e, consequentemente, impactar negativamente a qualidade do software.
- A qualidade não deve ser preocupação de uma pessoa ou equipe, deve ser preocupação de todos os que estão trabalhando na criação do software.
- A qualidade é um requisito não funcional, ou seja, que especifica um critério para avaliar o funcionamento de um produto digital, enquanto requisito funcional especifica um comportamento do software. Desempenho, escalabilidade, operabilidade, monitorabilidade são alguns exemplos de requisitos de software não funcionais que são tão importantes quanto a qualidade. Mesmo assim, não há funções definidas para garantia de desempenho, garantia de escalabilidade, garantia de operabilidade e garantia de monitorabilidade. Por que a qualidade é o único requisito não funcional que tem uma função específica dedicada para garanti-la?
- O controle de qualidade se concentra em garantir a qualidade do processo de desenvolvimento de software. Se uma função separada é necessária para garantir essa qualidade, por que não há necessidade de uma função separada para garantir a qualidade do processo de gestão de produto, o processo de design, o processo de marketing de produto, o processo de vendas, o processo financeiro de uma empresa?
- Havia uma preocupação de que, se o próprio engenheiro agora tivesse que testar, as entregas demorariam mais para ficar prontas. Essa preocupação existia porque os engenheiros consideravam que seu trabalho estava concluído – e a entrega estava pronta – quando passavam a história para o QA testar. No entanto, o conceito de pronto do engenheiro está incorreto, pois ele acabou de passar a história para a próxima fase, o teste. Do ponto de vista do usuário, a história só está pronta quando o usuário pode usar o novo recurso. Portanto, o tempo que a entrega permanece no controle de qualidade ainda é o tempo de desenvolvimento, mesmo não estando mais nas mãos do engenheiro. E esse tempo fica ainda maior quando a história passa pelo controle de qualidade, mas é rejeitada e precisa voltar para a engenharia.
Quando entrei na Conta Azul, eles também haviam acabado de extinguir a função de QA, e os ex-QAs passaram a ser analistas de negócios, principalmente ajudando gerentes de produto.
Eu vi outras empresas também discutindo a necessidade de QAs e, em alguns casos, um debate acalorado emerge em torno deste tópico. No entanto, ter ou não ter QAs não deve ser o centro da discussão. Ter ou não ter essa função é a solução de um problema, normalmente referido como “como podemos melhorar a qualidade do nosso produto?”, e esse problema deve ser o centro da discussão.
Como podemos melhorar a qualidade do nosso produto?
Uma simples pesquisa no Google sobre qualidade de software produzirá toneladas de definições normalmente relacionadas ao atendimento de requisitos funcionais e não funcionais. Quando o software não atende a um requisito funcional ou não funcional, ele apresenta um defeito, um bug. Portanto, para melhorar a qualidade de um produto de software, precisamos trabalhar em duas coisas:
- reduzindo seus bugs existentes;
- não gerando novos bugs.
Uma boa maneira de controlar isso é ter uma medição semanal de seu inventário de bugs e novos bugs por semana e discutir isso todas as semanas com a equipe. Fizemos isso no Gympass. Definimos no início de cada trimestre qual é a meta para o inventário de bugs e a média de novos bugs por semana.
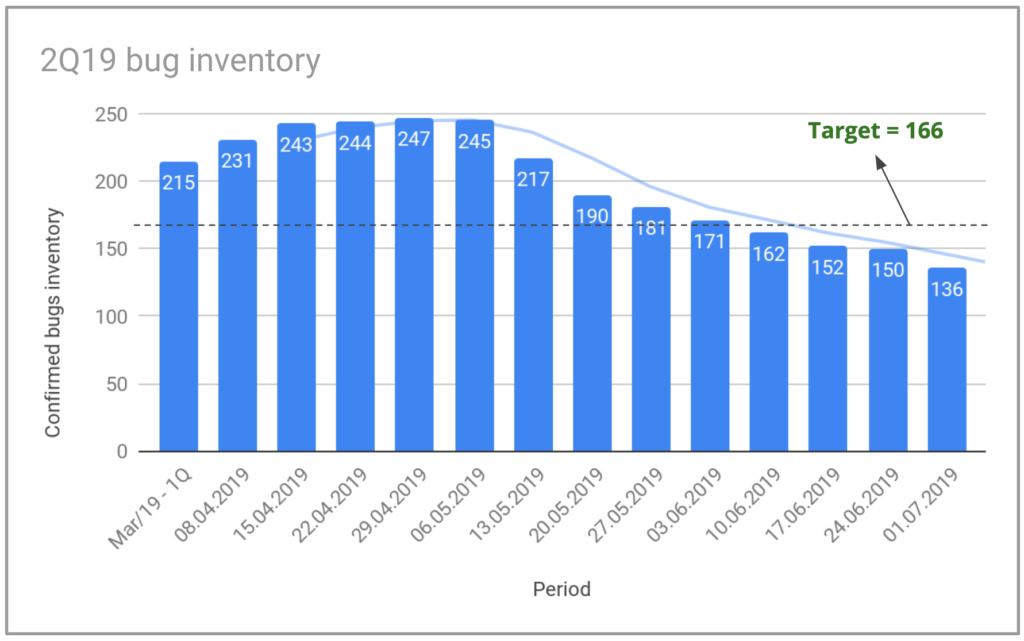
A imagem mostra a evolução do nosso estoque de bugs para o 2º trimestre de 2019. Iniciamos o trimestre com 215 bugs em nosso estoque e almejamos uma meta de menos de 166 ao final do trimestre, uma redução de quase 23%. Fechamos o trimestre com um estoque de 136 bugs, uma redução de 36%. Fizemos isso nos concentrando não apenas na resolução de bugs em nosso inventário, mas também no controle do número de novos bugs por semana.
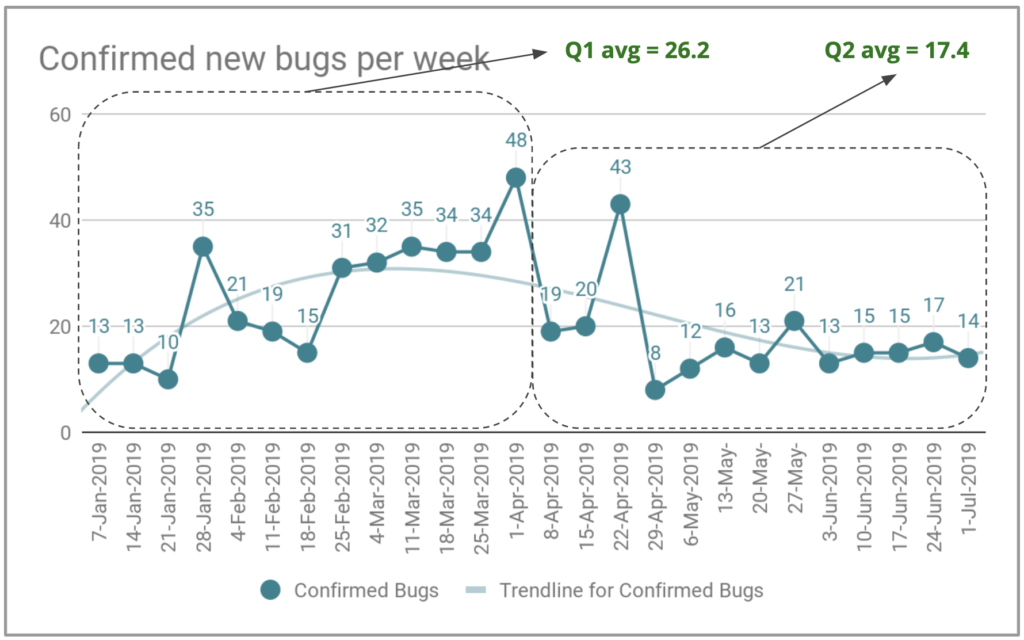
No primeiro trimestre de 2019, tivemos uma média de 26,2 bugs criados por semana. Durante o segundo trimestre, reduzimos essa média para 17,4 novos bugs por semana, para um total de 226 novos bugs durante o trimestre. Isso é uma redução de 33% no número de novos bugs por semana.
Isso parece uma melhoria muito boa, certo? Mas há muito espaço para melhorias aí. Deixe-me explicar a matemática do gerenciamento de bugs:
Se fomos capazes de reduzir nosso estoque de bugs de 215 para 136, isso significa que resolvemos pelo menos 79 bugs. No entanto, criamos 226 novos bugs (17,4 novos bugs por semana x 13 semanas) durante o trimestre. Resolvemos 79 + 226 = 305 bugs durante o trimestre, é muito trabalho de correção de bugs. Se tivéssemos gerado 90 novos bugs durante o trimestre, uma média de 6,9 novos bugs por semana, em vez dos 226 novos bugs, poderíamos ter zerado o inventário de bugs.
Um aspecto adicional da resolução do bug a ser medido é o SLA (Service Level Agreement) de resolução, ou seja, quantos dias a equipe levou para resolver um bug a partir do dia em que o bug foi identificado pela primeira vez. Para isso, classificamos os bugs pela sua gravidade, que é o impacto que causa aos usuários e ao negócio. Os bugs de maior gravidade são aqueles que precisamos resolver no mesmo dia; erros de alta gravidade, em 7 dias e média de gravidade, em 14 dias. O gráfico a seguir mostra como estávamos no Gympass no quarto trimestre de 2019.
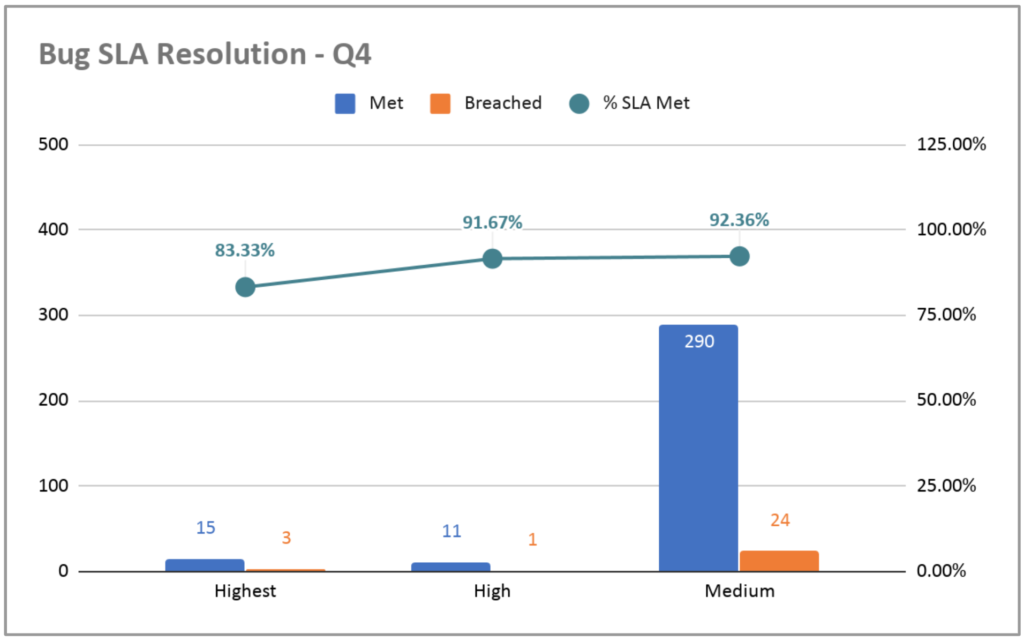
Essa não é a visualização ideal porque mostra apenas uma imagem do momento, e não uma evolução. Para entender a evolução de qualquer métrica, você precisa ver como ela se saiu em diferentes pontos no tempo.
Assim que me juntei à Lopes, comecei a trazer esse tema para a discussão com os times. Uma das coisas que notamos é que 50% dos itens “deploiados” era correção de bugs. Fui informado de que “esses bugs eram pegos antes de ir para produção, o que é algo bom”. De fato, ainda bem que esses bugs não chegaram ao ambiente de produção e apareceram para nossos usuários. Contudo, eles chegaram à pré-produção e precisavam ser corrigidos. Não seria melhor se esses erros nem sequer existissem, nem mesmo em pré-produção?
Os OKRs que definimos para nos ajudar com o tema qualidade foram 3 KRs adicionais no objetivo de Aumentar a cadência de deploys em produção que comentei no capítulo anterior:
- KR: Reduzir o número de novos bugs para 5% em pré-produção.
- KR: Reduzir o número de bugs totais para 10% em pré-produção.
- KR: Manter o número de bugs totais abaixo de 5% em produção.
E adicionamos o seguinte OKR:
- Objetivo: Melhorar a qualidade das entregas das squads.
- KR: Revisar 100% das novas histórias para encontrar requisitos mal definidos e/ou ambíguos.
- KR: Efetuar revisão de 25% dos Pull Requests dos squads.
- KR: Mensurar volume de Pull Requests dos squads.
Outro exemplo de controle de bugs
Na Conta Azul dobramos o time de desenvolvimento de produtos em um período de 8 meses entre novembro de 2017 e julho de 2018. Esse crescimento tinha por objetivo aumentar a capacidade produtiva do time.
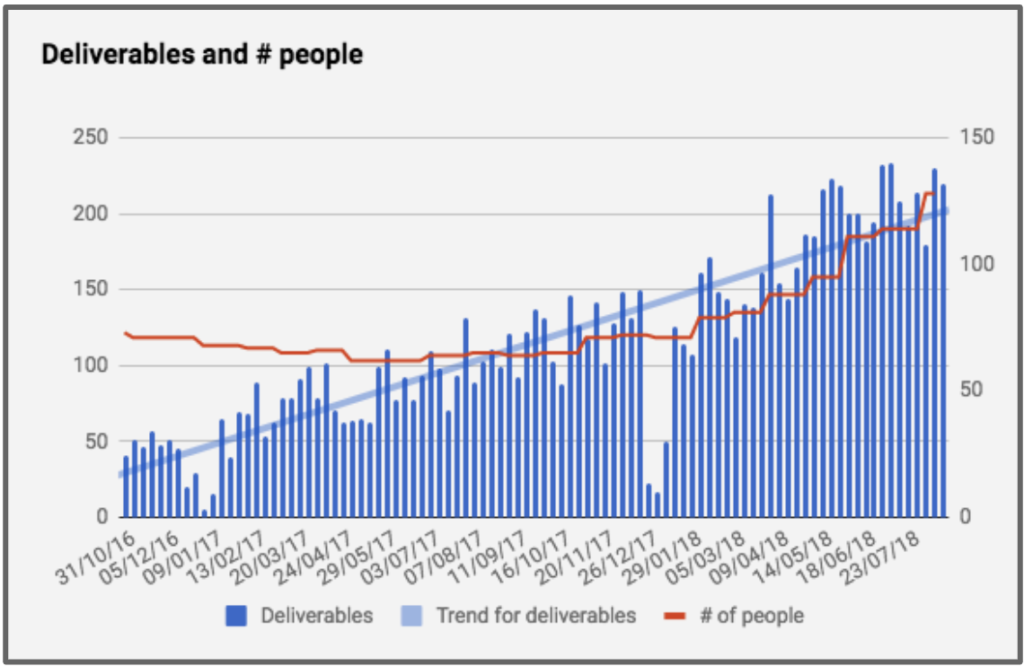
Além disso dividimos a quantidade de entregas pelo total de pessoas no time para avaliar se estávamos conseguindo aumentar nossa produtividade individualmente.
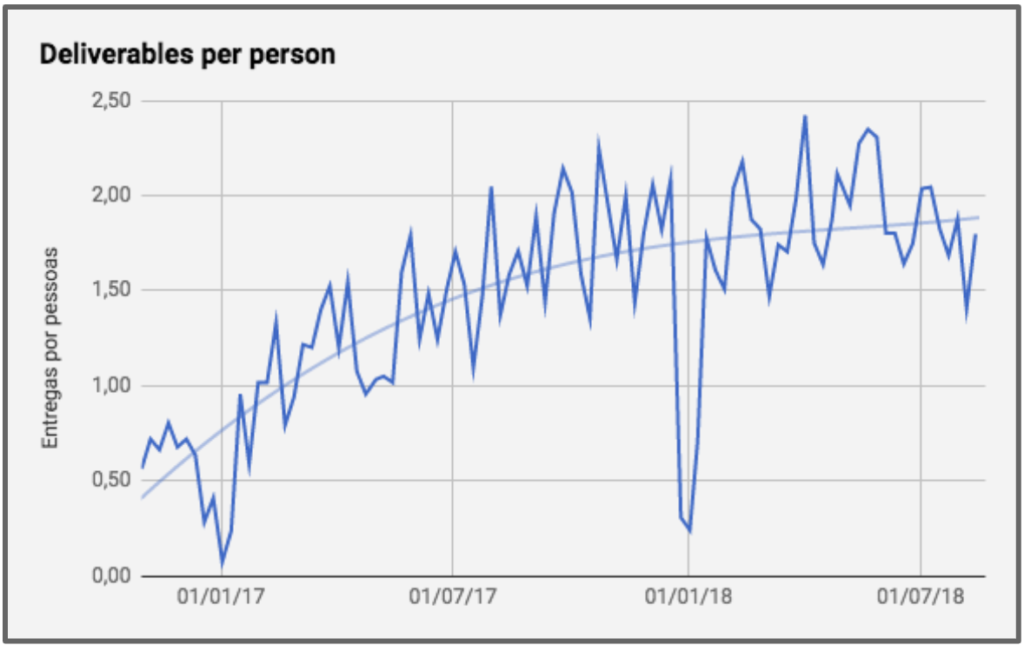
Contudo, com o aumento de pessoas no time, acabou aumentando a quantidade de bugs. Tanto que o time que já vinha tendo 40% de suas entregas como correção de bugs acabou tendo que aumentar essa proporção para 60%. Ou seja, apesar de ter aumentado a produtividade individual e total, esse aumento de produtividade não estava sendo sentido pelo usuário, pois acabava sendo usado para refação.
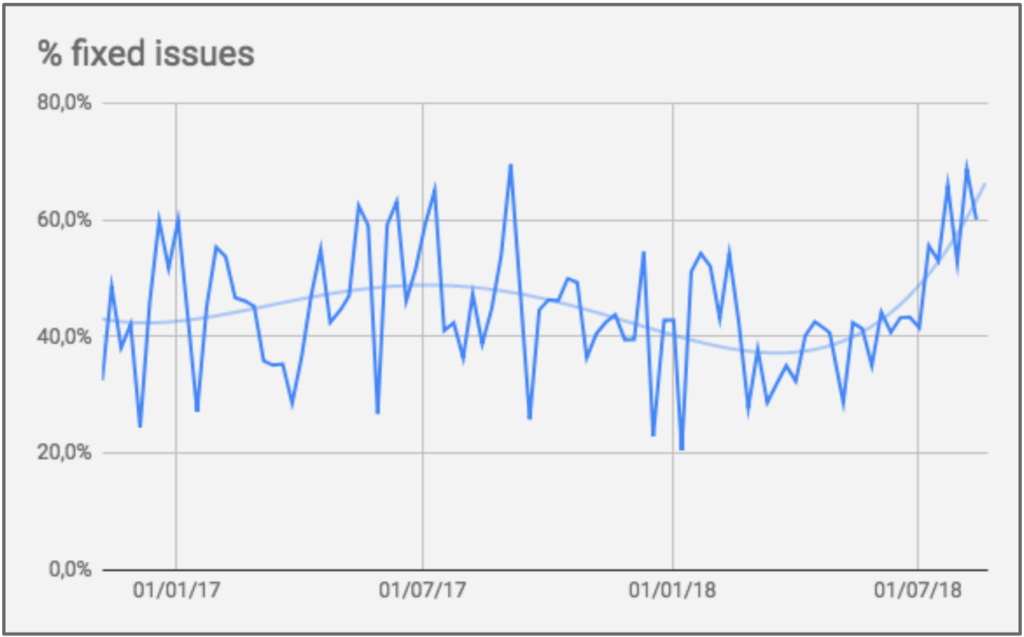
Para controlarmos esse problema, aumentamos nosso foco em corrigir esses bugs dentro dos SLAs, que eram:
- 85% dos chamados resolvidos em até 7 dias
- 98% dos chamados resolvidos em até 30 dias
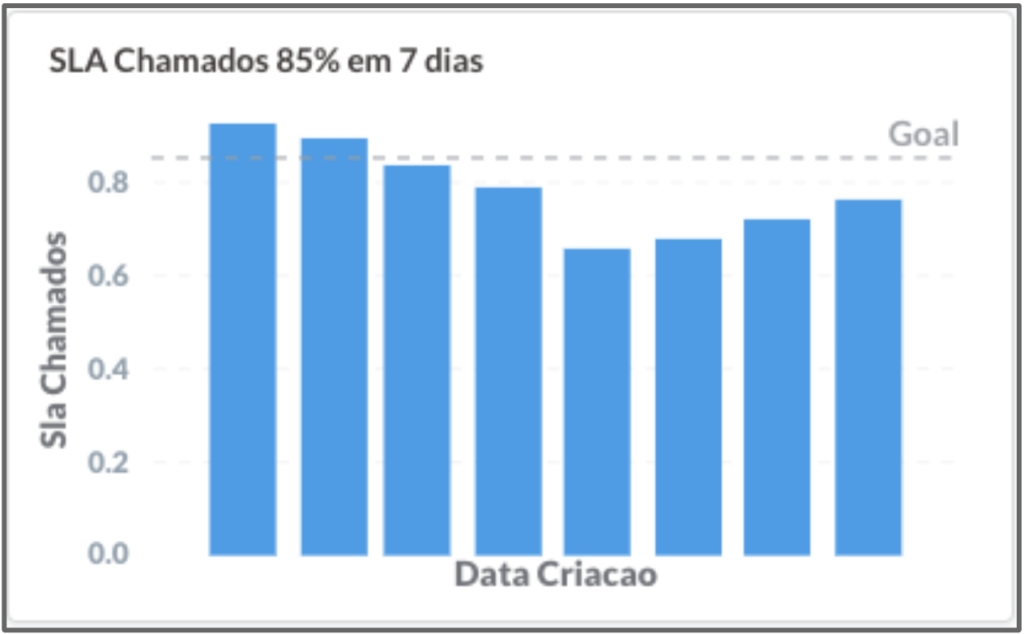
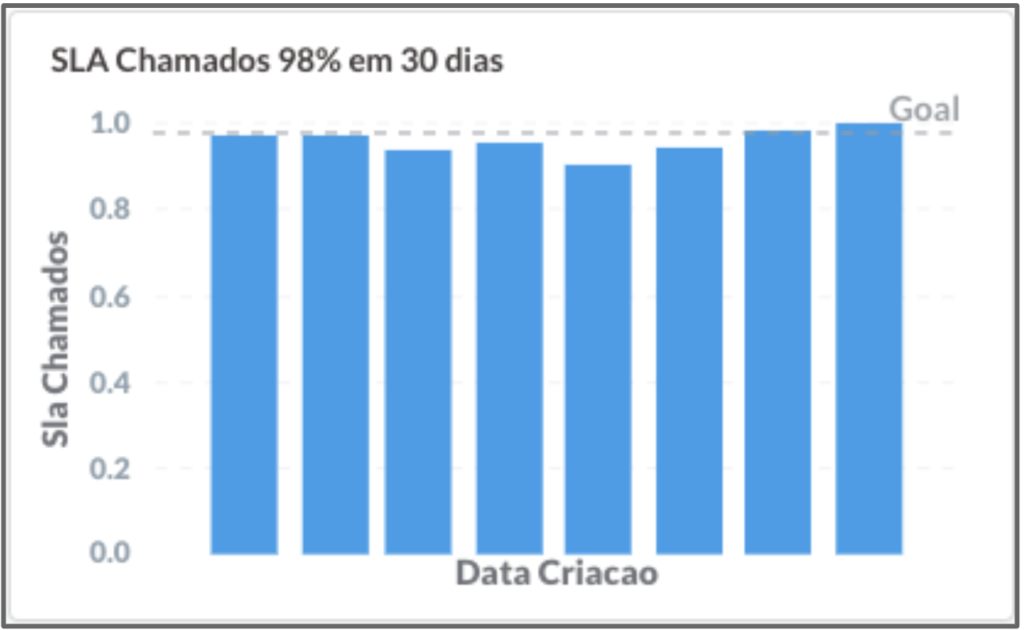
Veja que a qualidade piorou e o cliente sofreu com isso. Mas, depois de algum tempo, conseguimos retornar aos níveis de SLA definidos. Olhávamos essa métrica semanalmente e, sempre quando discutíamos sobre essa métrica, concordávamos que a melhor maneira de cumprir o SLA era não criar bugs!
Qualidade não é só controle de bugs
Além do controle de bugs, há vários outros aspectos que impactam na qualidade do produto digital que entregamos para os usuários. Desempenho, escalabilidade, operabilidade, monitorabilidade são alguns exemplos de requisitos não funcionais.
Quando me juntei ao Gympass, na minha segunda segunda-feira o sistema ficou fora para os usuários por volta das 19:00. Comecei a perguntar para as pessoas do time o que estava acontecendo e a resposta foi que as segundas-feiras são dias de pico de visita às academias e que às vazes o sistema não dava conta do volume. Como não havia monitoração, não éramos alertados de que o volume estava maior que o usual e não conseguíamos nos preparar adequadamente. Dois meses depois, quando o Rodrigo Rodrigues se juntou ao Gympass como CTO, ele apelidou o evento de “Back Mondays”. Para endereçar o problema passamos a monitorar e implementar uma infraestrutura que desse conta dos picos das segundas-feiras. E definimos OKRs para uptime, requests de HTTP bem-sucedidos e tempo de reposta do backend.
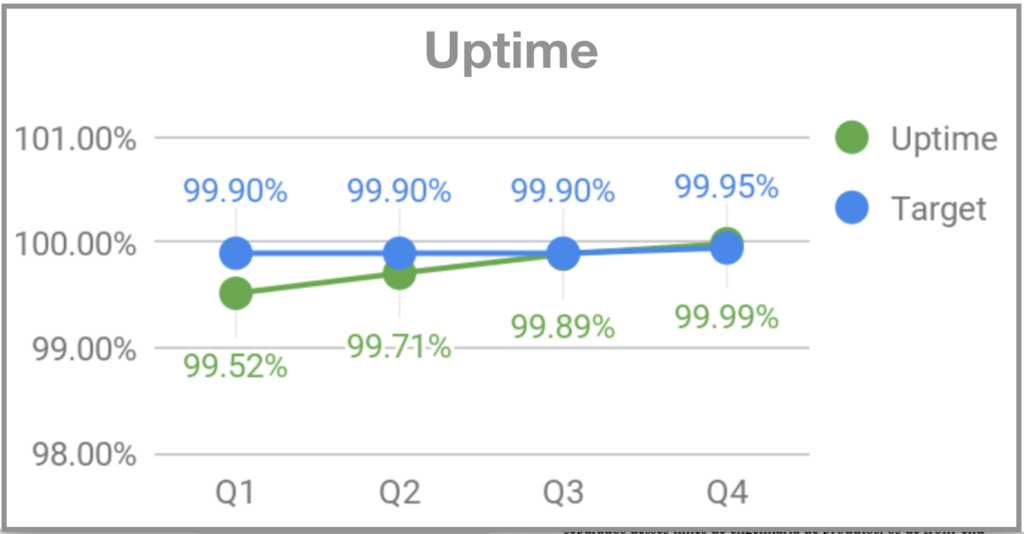
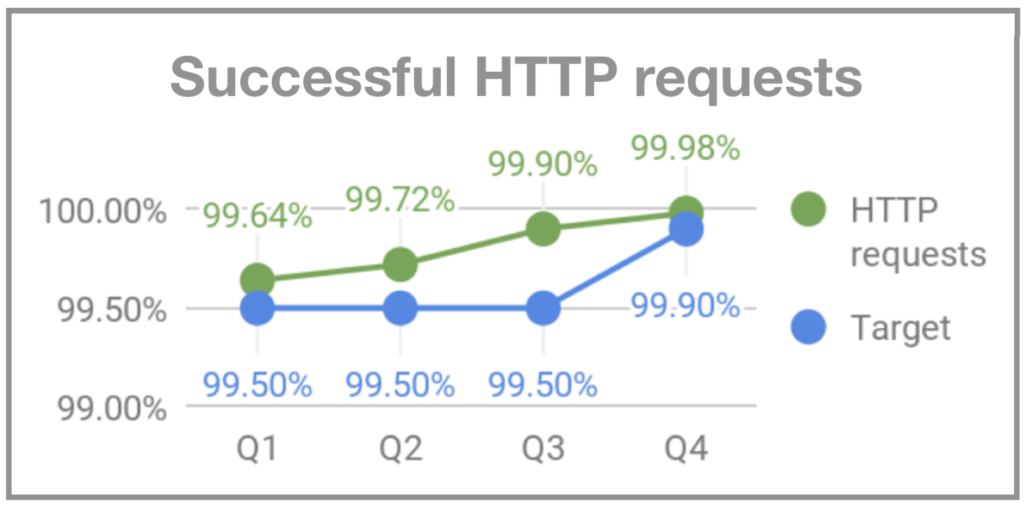
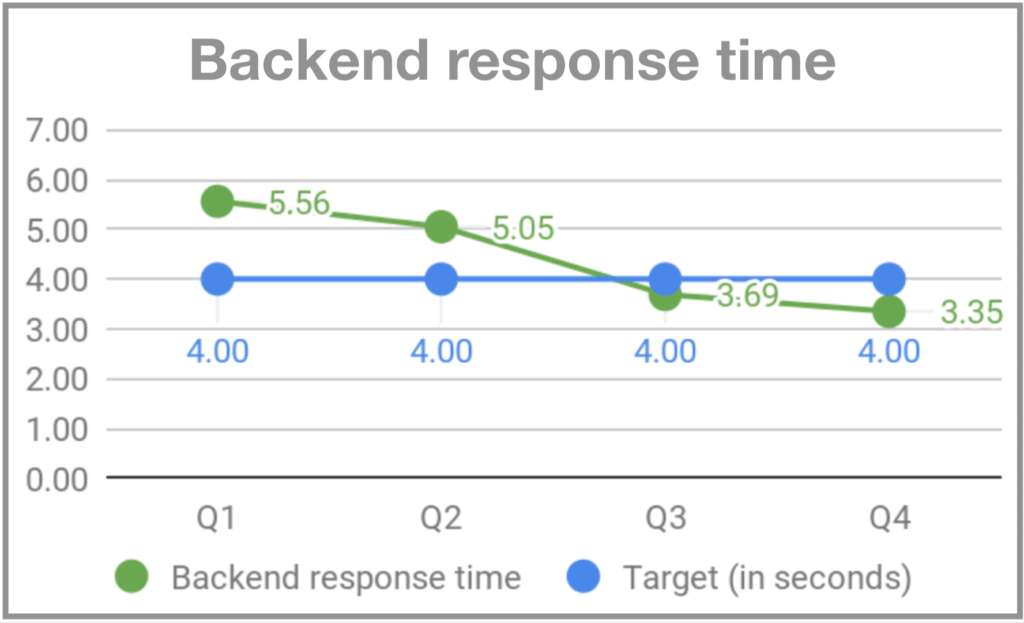
Por que a qualidade é tão importante?
Qualquer usuário prefere utilizar um produto de boa qualidade que se comporte conforme o esperado. Isso é condição sine qua non para fornecer uma boa experiência do usuário.
Além da experiência do usuário, há outro aspecto importante a considerar quando falamos sobre qualidade e bugs. Sempre que alguém precisa trabalhar na resolução de um bug que foi encontrado em um produto digital, essa pessoa precisa parar de trabalhar no que quer que esteja trabalhando no momento para poder resolver o bug. Esta é uma interrupção no fluxo de trabalho. Se essa pessoa fosse capaz de entregar o software sem aquele bug, ela poderia continuar a trabalhar em coisas novas sem interrupções, o que a tornaria mais produtiva.
A relação entre produtividade e qualidade
Tive a oportunidade de participar de um curso do MIT sobre como criar organizações de alta velocidade. O curso foi ministrado pelo Professor Steven J. Spear, autor do livro The High-Velocity Edge: How Market Leaders Leverage Operational Excellence to Beat the Competition. Esse é um daqueles cursos muito densos, cheios de conteúdo, mas que pode ser resumido em um parágrafo:
Organizações de alta velocidade são capazes de aprender muito rápido, especialmente com suas falhas, e de absorver esse aprendizado como parte integrante do conhecimento da organização.
Uma organização de alta velocidade trabalha seguindo os 4 passos adiante:
- Estar preparado para capturar conhecimento e encontrar problemas em sua operação.
- Entender e resolver esses problemas para construir novos conhecimentos.
- Compartilhar o novo conhecimento com toda a organização.
- Liderar para desenvolver habilidades 1, 2 e 3.
O exemplo clássico é a Toyota, com a manufatura enxuta e o conceito de parar a produção sempre que houver falhas, corrigindo-as e usando-as como oportunidade de aprendizado para que não aconteçam mais. Essa capacidade de aprender com as falhas é o que dá à Toyota a capacidade de permanecer à frente de seus concorrentes por tanto tempo.
Outro bom exemplo é a Alcoa, que tinha uma taxa de incidentes de trabalho de 2% ao ano, considerada normal. A Alcoa tem mais de 40.000 funcionários, portanto, 2% dos incidentes de trabalho por ano significa que 800 funcionários por ano têm algum tipo de incidente de trabalho. Esse é um número bastante impressionante e preocupante.
Para combater esse problema, eles implementaram uma política de tolerância zero a erros. Antes de implementar esta política, os erros eram vistos como parte do trabalho. Agora, os funcionários são incentivados a relatar erros de operação em 24 horas, propor soluções em 48 horas e contar a solução encontrada para seus colegas para garantir que o conhecimento se espalhe por toda a organização.
Isso fez com que o risco de incidentes caísse de 2% para 0,07% ao ano! Essa redução na taxa de incidentes significava que menos de 30 funcionários por ano tinham algum problema de incidente de trabalho depois que a política de tolerância a erro zero foi implementada e a Alcoa obteve um aumento de produtividade e qualidade semelhante ao da Toyota.
Falhar rápido vs. aprender rápido
Um fator importante nos exemplos da Toyota e da Alcoa é que reconhecer e aprender com as falhas deve fazer parte da cultura da empresa. Isso é algo um pouco mais comum na cultura das empresas de tecnologia, mas não tão comum em empresas tradicionais. Durante o curso do MIT dividi mesa com um executivo brasileiro, do Grupo Globo, um executivo espanhol, da AMC Networks International (Walking Dead, Breaking Bad e Mad Men), um gerente de projetos alemão residente no Azerbaijão que trabalha para a Swire Pacific Offshore (indústria de petróleo e gás) e uma estudante de pós-doutorado do MIT em energia solar vinda da Arábia Saudita.
Todos os meus companheiros de mesa eram de indústrias mais tradicionais. Eu era o único de uma empresa de internet. Os executivos da Globo e da AMC estavam lá porque viram a Netflix com seu streaming de vídeo sob demanda e o YouTube com seu enorme catálogo de vídeos gerados por usuários como grandes ameaças, roubando seu público muito rapidamente e eles queriam entender como poderiam se defender.
Embora o tema seja um tanto óbvio para as empresas de internet, especialmente com a cultura de startups de tecnologia que valorizam o fail fast (falhar rápido). É isso que torna a Netflix e o YouTube uma ameaça às empresas de mídia tradicionais, como o Grupo Globo e AMC Networks. No entanto, mesmo isso sendo parte da cultura das empresas de internet, sentar e discutir isso com pessoas de empresas mais tradicionais foi uma grande oportunidade de reflexão sobre a relação entre a falha, o reconhecimento da falha, o aprendizado e a alta velocidade:
- Reconhecer as falhas e usar as falhas como uma oportunidade de aprendizagem deve estar bem enraizado na cultura da organização. Se as pessoas não tomarem cuidado, à medida que uma empresa cresce, ela pode perder a capacidade de aceitar as falhas como oportunidades de aprendizado. É muito comum que as empresas, à medida que cresçam, sejam cada vez mais avessas a falhas e criem uma cultura que, em última análise, incentive as pessoas a esconderem erros e falhas.
- Outro aspecto importante do aprendizado com as falhas é tornar esse processo um padrão da empresa. Não adianta falhar, reconhecer o erro, afirmar que você não vai mais cometer aquela falha e, algum tempo depois, cometê-la novamente. Esse processo de aprendizado com as falhas deve fazer parte da cultura da empresa. Sempre que uma falha é identificada, o aprendizado deve acontecer o mais rápido possível para evitar que ela aconteça novamente. Se a mesma falha acontecer novamente, algo está quebrado no processo de aprendizagem com a falha.
- Mesmo em empresas de internet, percebo que aprender com as falhas é mais comum na equipe de desenvolvimento de produtos, uma vez que retrospectivas e aprendizado contínuo fazem parte da cultura de desenvolvimento ágil de software. Em outras áreas da empresa, aprender com as falhas é menos comum. Essa capacidade de sistematizar o aprendizado com o fracasso deve permear toda a empresa.
Mesmo que ouçamos muito sobre a cultura das empresas de internet de falhar rápido, falar sobre falhar rápido diverge nosso foco do que é realmente importante, aprender rápido. Devemos colocar nossa energia no aprendizado, não no fracasso. É o processo de aprendizagem que faz evoluir pessoas e empresas. E é a capacidade de uma organização aprender rápido, principalmente com seus fracassos, que vai permitir que ela se mova em velocidades realmente altas.
Resumindo
- Questionar se o desenvolvimento de produto deve ou não ter uma equipe de QA dedicada não é a pergunta certa.
- O problema que você está tentando resolver é como melhorar a qualidade do seu produto.
- Uma boa métrica proxy de qualidade são os bugs. Inventário de bugs, novos bugs por semana e SLA de resolução de bugs.
- Uma equipe de desenvolvimento de produto deve ter todos os seus membros seguindo essas métricas e agindo para melhorá-las.
- Gerir bugs não é suficiente para gerir a qualidade do produto digital. Desempenho, escalabilidade, operabilidade, monitorabilidade são alguns exemplos de requisitos não funcionais que impactam diretamente na qualidade do produto digital.
- A qualidade está em primeiro plano para fornecer uma boa experiência do usuário. Além disso, é fundamental para aumentar a velocidade de sua equipe de desenvolvimento de produto. Quanto menos bugs uma equipe tiver para corrigir, mais tempo ela terá para se concentrar em coisas novas.
- Organizações de alta velocidade são capazes de aprender muito rápido, especialmente com suas falhas, e de absorver esse aprendizado como parte integrante do conhecimento da organização.
No próximo capítulo vamos ver um pouco mais sobre métricas.
Liderança de produtos digitais
Este artigo faz parte do meu mais novo livro, Liderança de produtos digitais: A ciência e a arte da gestão de times de produto, onde falo sobre conceitos, princípios e ferramentas que podem ser úteis para quem é head de produto, para quem quer ser, para quem é liderado por ou para quem tem uma pessoa nesse papel na empresa. Você também pode se interessar pelos meus outros dois livros:
- Gestão de produtos: Como aumentar as chances de sucesso do seu software
- Guia da Startup: Como startups e empresas estabelecidas podem criar produtos de software rentáveis
