
How to increase the chances of success in a career transition to product management?
6 de April, 2024
Using product mindset in services, or is it the other way around?
23 de April, 2024How can we move faster? How can we deliver more with the same team? Why do we feel like the team is slow? When the team was smaller, it seemed like they could deliver more. These are common questions and statements I hear about product development teams. Every company with a digital product development team would like that team to be faster. For this reason, I’ll show you how we measured and managed productivity in the different teams I’ve led.
In my last year at Locaweb, we were focusing a lot on productivity, on how the product and software development teams at Locaweb could produce more without needing to add more people to the teams and without compromising the quality of the deliveries. The following chart shows our numbers. We tracked the number of deliveries per week, and as you can see, in some weeks, we more than quadrupled the number of deliveries per week:
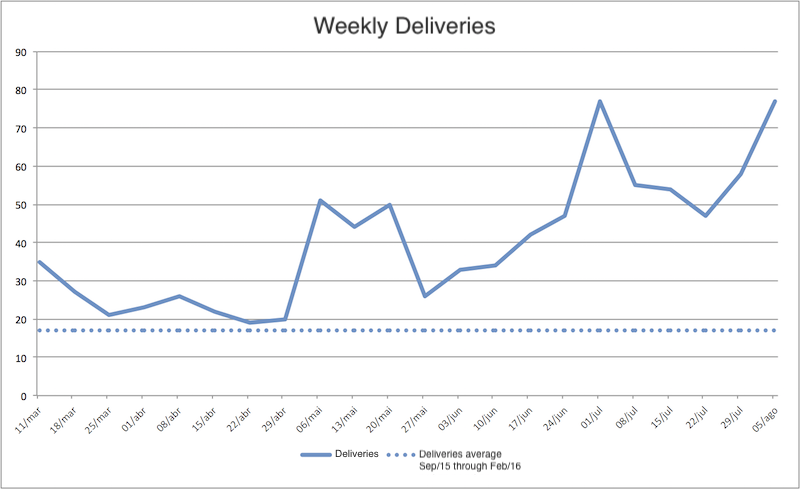 Deliveries per week at Locaweb.
Deliveries per week at Locaweb.
This increase in productivity occurred when the team grew by only 10% in terms of the number of people, so it’s not plausible to attribute this productivity increase solely to the growth in team size.
When there is such an increase, in addition to the natural question of whether the productivity boost is due to the increase in team size, another question that arises is whether there has been a decline in the quality of deliveries. One of the measurements of quality we make is the number of rollbacks. As you can see below, even with the increase in productivity, the number of rollbacks was reduced by 40%!
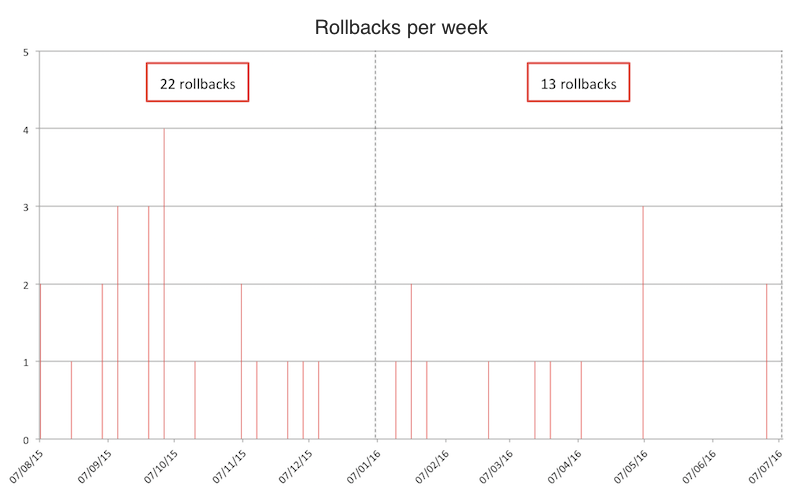 Rollbacks per week on Locaweb.
Rollbacks per week on Locaweb.
After I arrived at Conta Azul, we decided to implement the same type of control over weekly deliveries, and we were able to achieve a good increase in productivity as well.
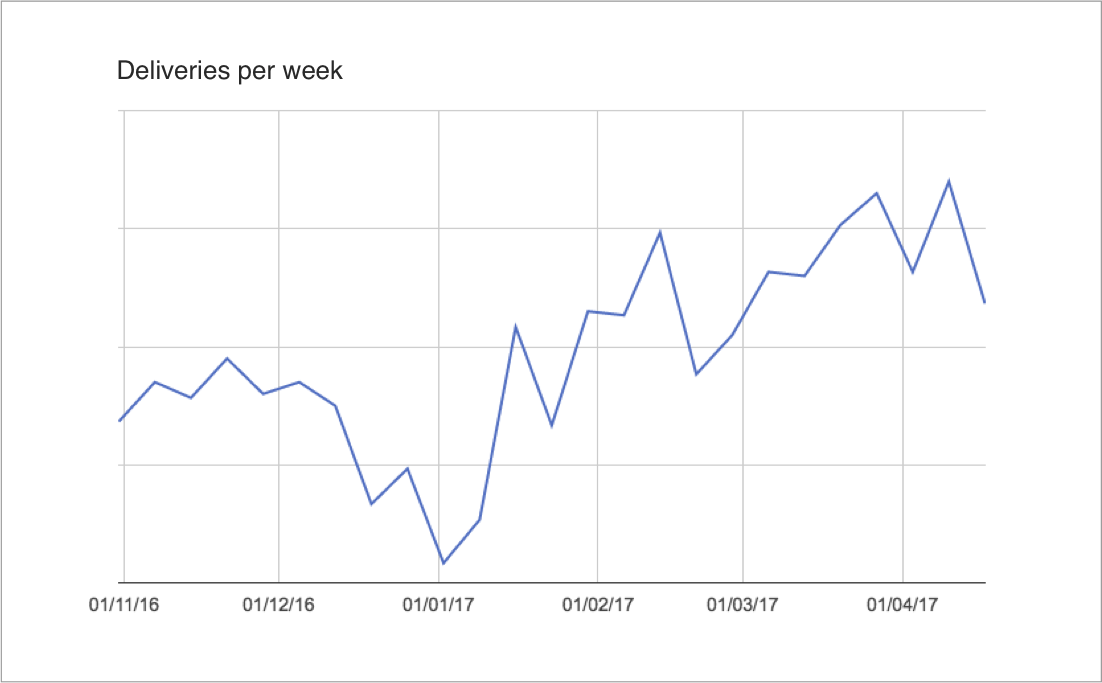 Deliveries per week at Conta Azul.
Deliveries per week at Conta Azul.
At Gympass, as we were rapidly expanding the team, we decided to monitor the number of deliveries per person per week. We counted the people who joined 2 months prior, as it takes 1 to 2 months for individuals to become productive. In one quarter, we were able to increase our productivity per person by 16%.
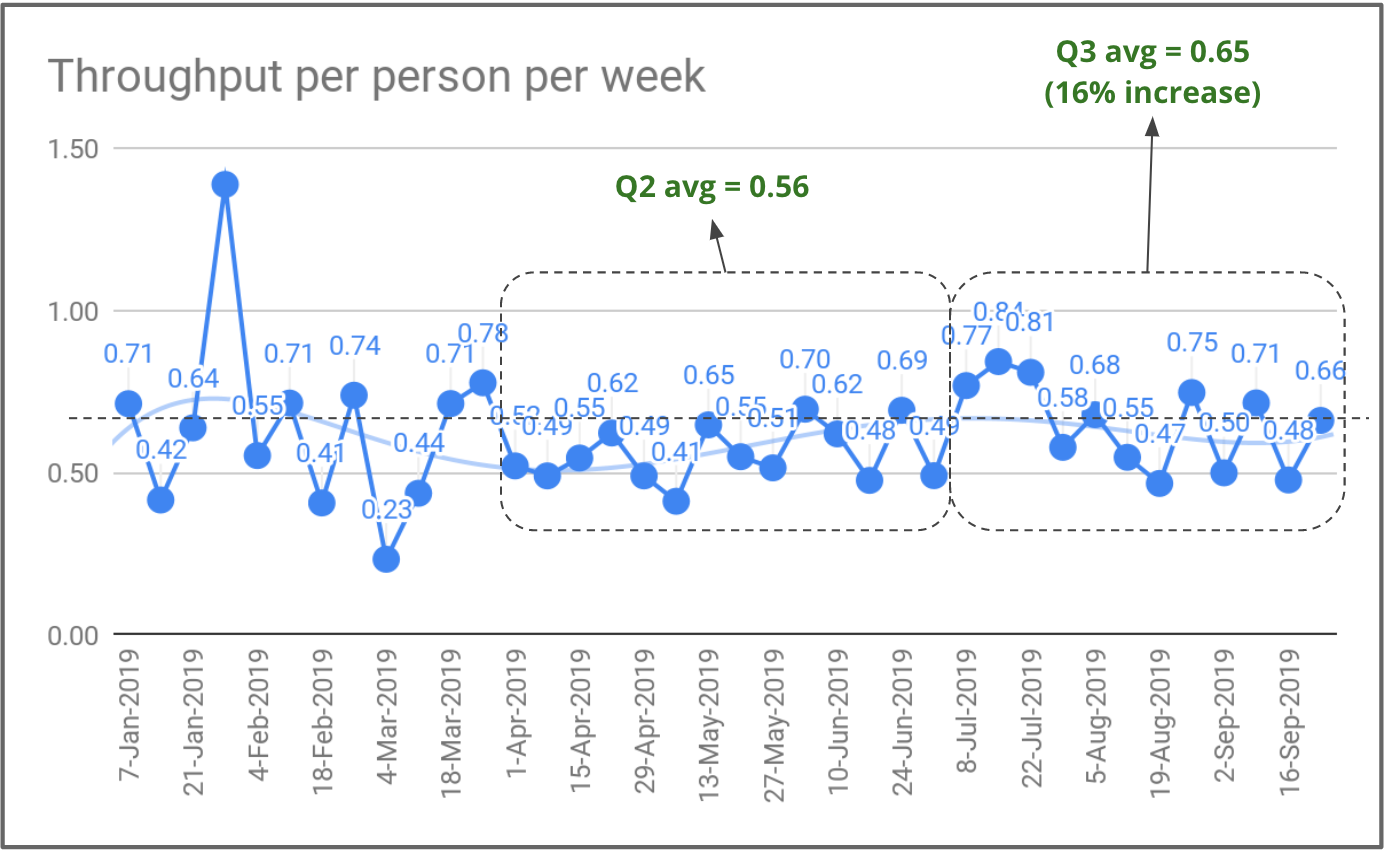 Deliveries per person per week at Gympass.
Deliveries per person per week at Gympass.
At Gympass, we also measured the number of deploys, both in our core, known as the monolith, and in microservices. We also achieved a considerable increase within a year.
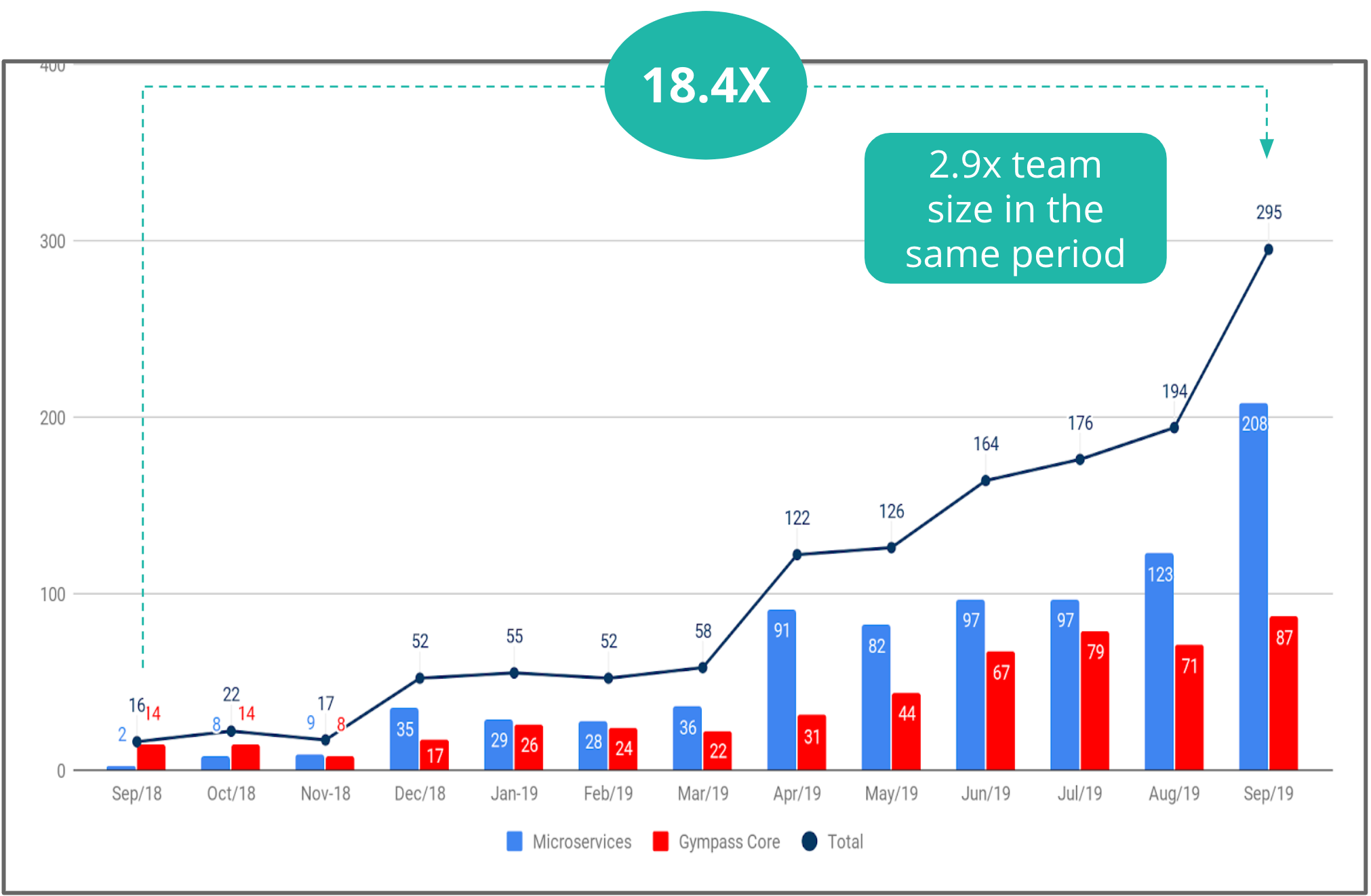 Deliveries per month at Gympass.
Deliveries per month at Gympass.
At Lopes, we also achieved a considerable increase. As soon as a deploy was made, an email was sent with a list of the “deployed” items. One of the first things I did was to compile these reports into a spreadsheet to build the chart below. It was easy to notice that deploys didn’t happen every day. On average, they occurred about once a week. Once we observed this, we set OKRs to increase the frequency of deploys, which has been effective. The OKRs we defined were:
- Objective: Increase the cadence of deploys in production;
- KR: Increase the number of deploys per week to a minimum of 3 (more is better);
- KR: Reduce the maximum number of new features per deploy to a maximum of 10.
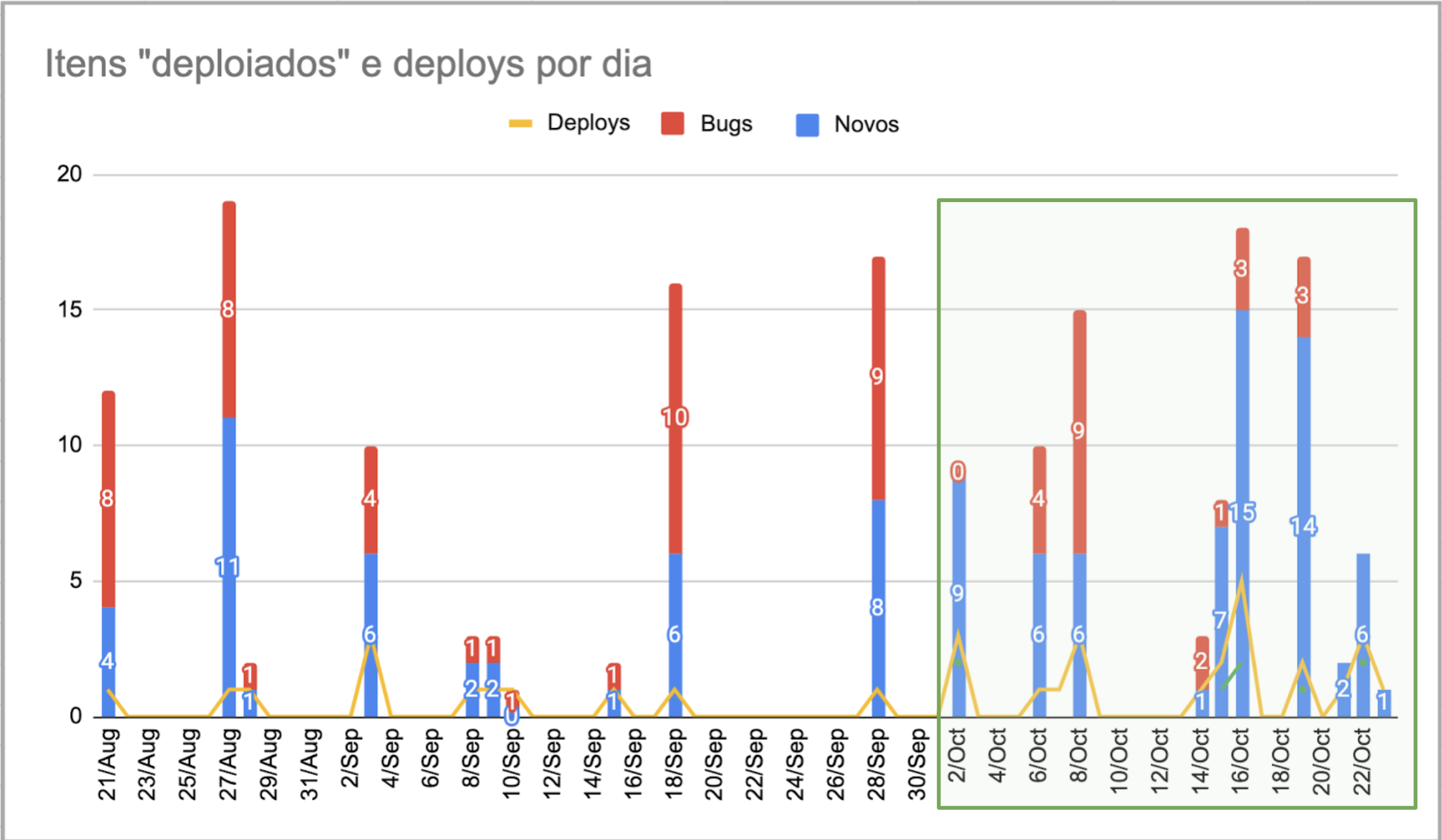 Deploys per day at Lopes.
Deploys per day at Lopes.
Comparing the two periods, we have:
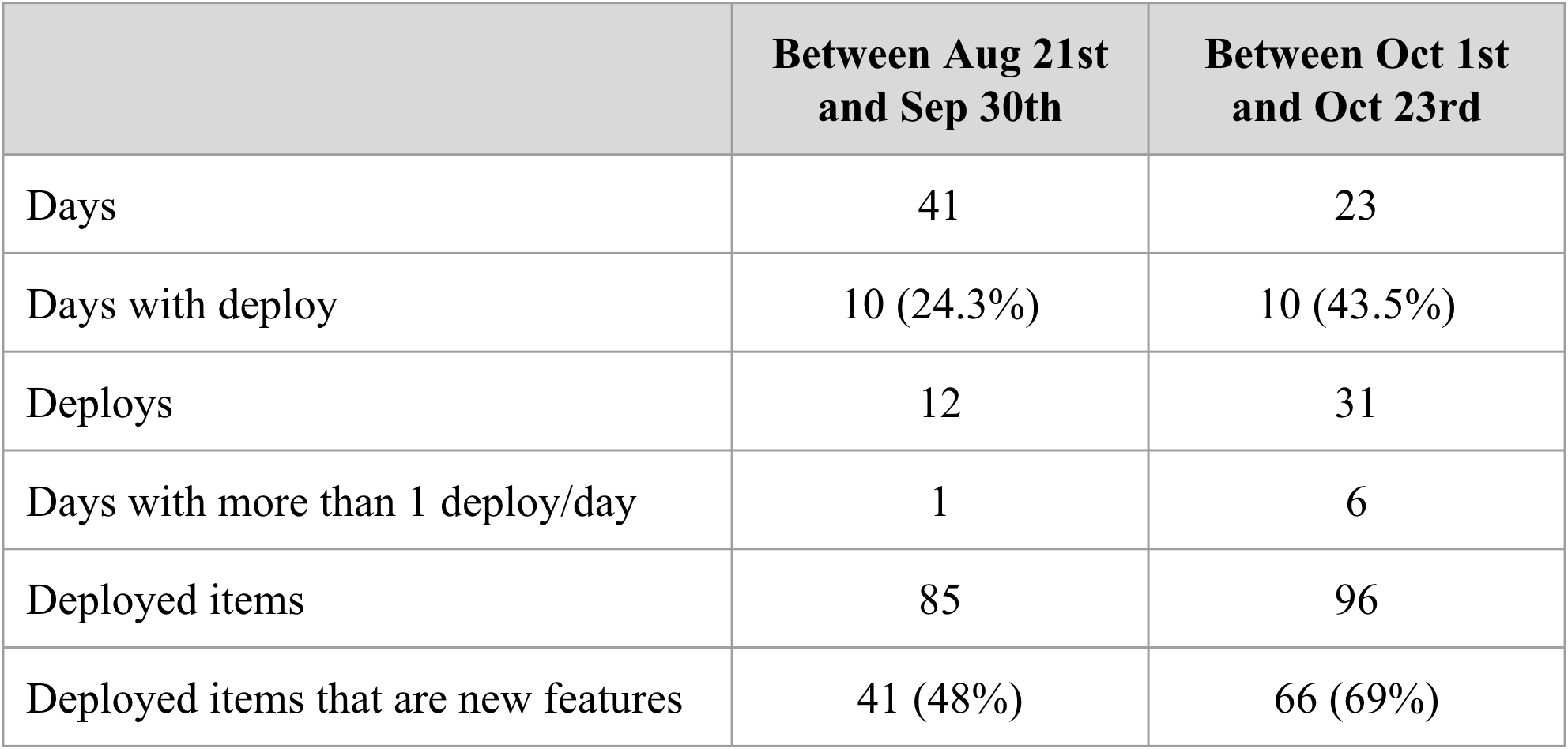
How do we achieve this?
There is no silver bullet: there were several actions we took, and we are sure that there are still more actions that could be taken to increase productivity further. Here’s a list of what we did at Locaweb to increase the productivity of the product development team, practices that I later brought to other companies.
Measure
First and foremost, to improve anything, you need to measure it to know if it’s improving! We made some estimated calculations of deliveries per week from September 2015 to February 2016. The calculation was quite simple: the total number of deploys made in the period divided by the number of weeks. We then started communicating to the entire company about the weekly deliveries.
At Locaweb and Conta Azul, each product manager would send me the deliveries of the week on Fridays. I would compile the data, note the quantity for each week, and generate this chart. Once we started measuring, the level at which we were operating became clearer, and the actions we implemented began to show results on the chart. Additionally, the teams started using a single measurement tool, Jira, which provided them with a better view of each team’s progress and allowed for sharing experiences, like, “look at this interesting chart, how did you manage to increase this metric?”
Kanban vs. sprint
Another change we made was transitioning from Kanban to sprint. Initially, all teams operated with Kanban. However, in Kanban, when an item has a blocker, it cannot be moved, and the team can’t do anything else, leading to a standstill. Occasionally, a team would move an item from “doing” to “to be done” due to a blocker, and pick another item to work on, which shouldn’t be done. Once in “doing,” the task can only go to “done” and cannot go back to “to be done,” losing control over productivity.
With sprints, the team organizes the next two weeks of work, plac- ing multiple items to be worked on. Thus, if one item encounters a blocker, the team can start working on another item and, thereby, deliver more within the same timeframe.
It’s essential to emphasize that this is not a critique of Kanban. This happened in 2015. I believe we didn’t have enough maturity and knowledge to get the best out of Kanban, so we chose to switch to Scrum.
Discovery and delivery
What the UX designer and the product manager do can be called discovery, which means figuring out what needs to be done. On the other hand, what engineering does can be called delivery, which is making and delivering what needs to be done. This separation of roles seems obvious, but not making it explicit within teams can hinder the software development process. Why? There are a few reasons.
The first is that if the discovery is not explicitly recognized, it’s not clear what is being done in this phase and what motivates certain decisions about what should be implemented in the software. It’s challenging to do something without knowing why you are doing it. The second reason is that when this separation is not explicit, items can go back and forth between delivery and discovery without clear criteria. It was not uncommon to see something being implemented by the engineers. When the UX team and the product manager saw their specification implemented, they wanted to make changes in the midst of development. With a clear separation between discovery and delivery, we established that once something goes into delivery, it doesn’t get changed. If you want to make changes, it has to go through a new discovery phase before going into delivery again.
Size of deliveries
In some cases, our deliveries were quite large, spanning several weeks or even a few months. As widely discussed in agile method- ologies, the frequent delivery of functional software is one of the principles of agility, reinforced by the practice of continuous delivery. A quick Google search will reveal numerous examples of top-tier companies making multiple deploys per day, with some even doing hundreds of them! :-O
To achieve this, the deploys need to be of small, very small deliv- eries. It’s essential to break down every large story into smaller ones. This is the work of the product manager in collaboration with the UX designer. I’ve been asked if this isn’t cheating, after all, instead of delivering one big story, we’re delivering the same thing but divided into small stories. It might seem like the same thing, but instead of delivering something significant after weeks or even months, we end up delivering value every day, allowing our users to enjoy the benefits rather than waiting for weeks or months.
Moreover, by deploying every day, we can learn from feedback and adjust future deliveries. There’s an additional benefit: the act of putting code into production every day makes the process of deploying code simpler, precisely because it’s done daily. So, delivering one big story over weeks or months is not the same as breaking that story into small pieces and delivering a small piece every day. There are clear productivity gains in delivering small pieces frequently.
Another additional benefit is that by making it easier for engineers to deploy (and rollback) code, it helps get the code into production more quickly.
When I left Locaweb, we were beginning to experiment with more points that had good potential to impact productivity, which we’ll explore in the next two topics.
First solution vs. simplest solution
It is human nature to want to solve problems. As soon as a problem arises, the initial reaction is to think of a solution and start implementing it to resolve the issue. However, the first solution is not always the best, both from the customer’s perspective and from the perspective of the solution implementer.
For this reason, we have preferred not to immediately start solving every new problem that arises. Instead, we first check if there are multiple possible solutions, analyze all the options, and then choose a solution to take action. Investing more time in thinking about other possible solutions, always keeping in mind the problem to be solved and why it needs to be solved, helps find simpler solutions. A simple solution (1 week of implementation) that resolves 70% to 80% of the problem is better than a complicated one (1 month of implementation) that resolves 100%. Most of the time, solving 70% to 80% of the problem is more than enough. Sometimes, the simplest solution is to do nothing!
For example, at Locaweb, the hosting and email service may stop working for a reason external to the service. The domain linked to hosting and email, which is paid annually to Registro.br, may not have been renewed. When it is not renewed, the services associated with that domain stop working, even if everything is operating perfectly at Locaweb. Recently, Registro.br made it possible for Locaweb to charge the customer’s domain on behalf of Registro.br. Initially, the idea seems good because by charging, we ensure that the customer knows they have to pay for this domain to keep the services running. However, upon closer analysis, we saw that this solution could create more problems.
The customer would receive two charges for the same thing, the domain registration, as Registro.br would continue to charge them. What happens if they pay both charges? What if they pay only Registro.br’s charge? What if they pay only Locaweb’s charge? Additionally, implementing a new type of billing, in which we would charge for the third-party service, would be something new for the team and for Locaweb. New processes would have to be designed. We then started thinking if there were simpler ways to solve the problem of helping our customer remember to pay for their domain registration at Registro.br.
Since for accessing information that the domain is about to expire it is necessary to charge Registro.br, we thought of the following solution: let’s implement a communication schedule with this customer, notifying them of the importance of paying Registro.br to ensure that the service continues to function. This is a much simpler solution than duplicating the billing process. If Registro.br also provides a direct link for domain billing, we can send this link in the communication. Thus, the chances of solving the problem increase even more, and a communication schedule is much simpler to implement than duplicated billing.
Choosing the most appropriate tool
Here, the topic is tools for implementing the solution— programming languages, frameworks, and databases. Each tool has its characteristics and is more suitable for solving certain types of problems. Choosing the right tool for each problem will impact productivity. This is a topic we are just starting to study now.
Currently, we use Rails for almost everything, but there are some problems that may be simpler and faster to solve by implementing a solution using another framework or language. Using a single programming language for all problems is like using a single tool for all the repairs that need to be done. Is a hammer the best tool for tightening a screw? Is Rails the best tool for managing queues?
We are confident that, with these two points we are starting to address now, we will be able to increase productivity by 10x or more! And surely there are other points that we haven’t even realized yet, and when we do and address them, they will have an even greater impact.
What impacts productivity?
The productivity of a product development team is influenced by various factors. Once, I came across a very interesting article writ- ten by the development team at Apptio (2019) in which they pre- sented a mind map illustrating all the elements that can positively or negatively impact the productivity of a product development team.
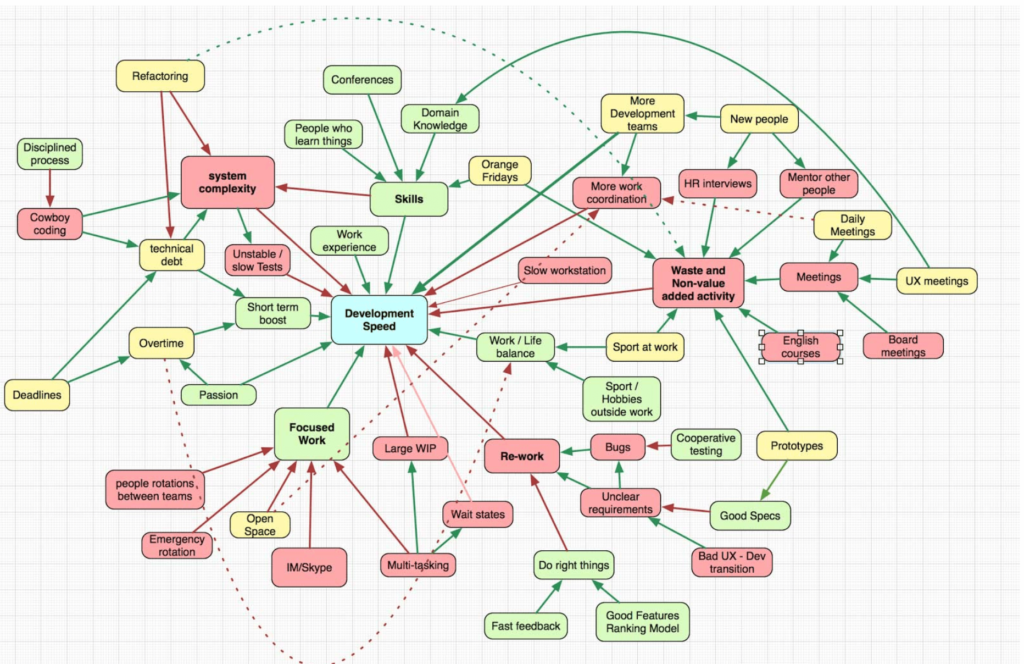 Apptio mind map of what impacts productivity. Adapted from: Apptio, 2019.
Apptio mind map of what impacts productivity. Adapted from: Apptio, 2019.
If you are reading this book in the print version or on a monochro- matic e-reader, you probably won’t be able to see all the colors and details in the image. Therefore, I recommend accessing the article2 where this image was published to view them.
This diagram illustrates things and activities that affect the de- velopment speed in some way. Green signifies that an activity increases speed. The more you have, the better. Yellow indicates that there is some maximum. For example, you can accumulate technical debt and increase speed, but if you accumulate too much, it will significantly slow you down. Red shows things that impede development, and the less you have, the better. The green arrow indicates increasing effect. For example, focused work increases development speed. The red arrow indicates decreasing effect. For example, better development skills reduce system complexity (skilled engineers create less complex systems).
What I like about this image is that it shows how complex this topic is and how many things can positively or negatively impact the team’s speed. At Conta Azul, we tracked this topic every quarter in the Product Council, a meeting where we discussed the quarterly planning of the product development team with leadership. There was a slide where we listed all the topics that could impact speed, discussing what we were doing about each of these issues:
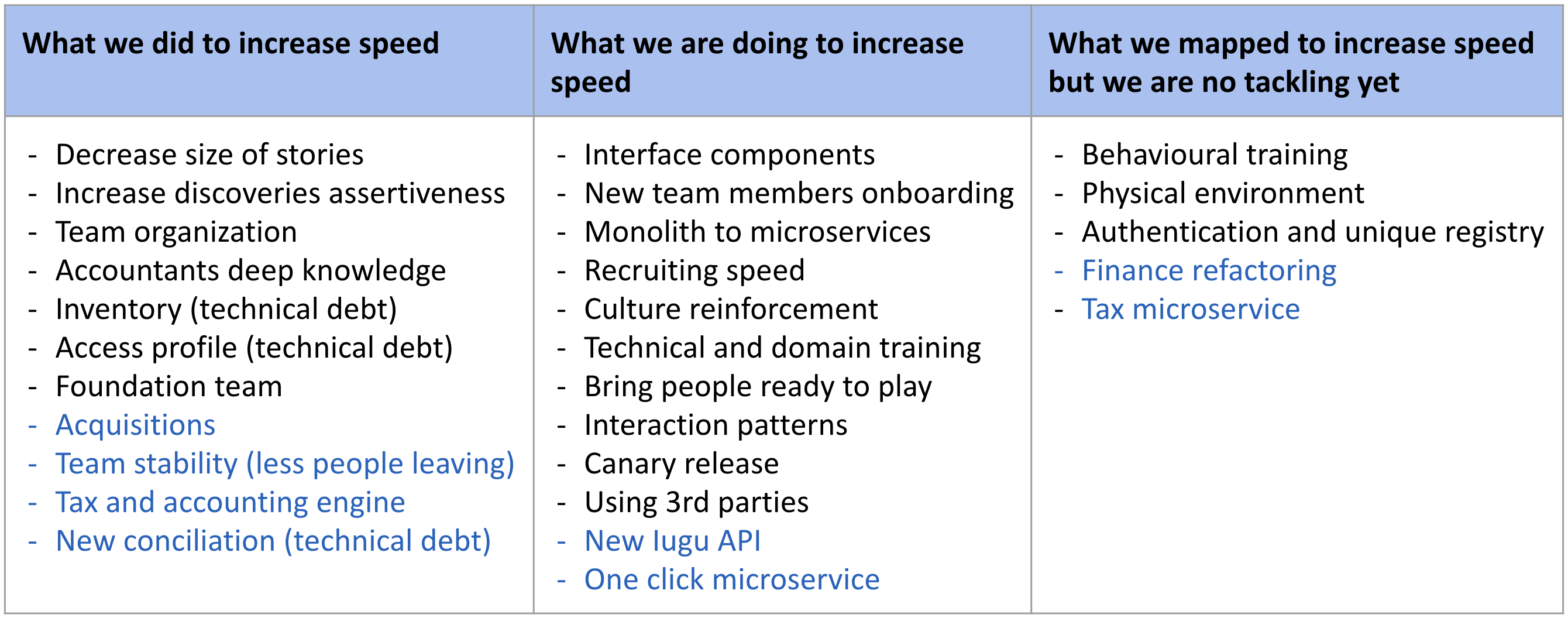 Topics that impact the speed of Conta Azul’s product development team.
Topics that impact the speed of Conta Azul’s product development team.
Put the topic of productivity at the center of the discussion
There is no silver bullet: with every team I’ve worked with, there have been various actions we’ve taken, and we’ve always been sure that by placing the productivity theme at the center of the discussion, there are more actions that can be taken to further increase productivity. The only silver bullet that exists is to make productivity an important theme in our conversations. Everyone started talking about productivity and what we could do to improve it.
This movement led us to initiate several changes and experiments that significantly increased our productivity. If you also want to boost the productivity of your product development team, make it a central theme in your conversations and experiment a lot. You will see how there is ample room for improvement in the productivity of your software development teams.
Another important point: don’t discuss the productivity theme sporadically. My recommendation is to do it weekly. Creating a weekly cadence will provide the opportunity to experiment with something new and discuss the results with the team every week.
What about quality?
As I mentioned earlier, when we increased the number of deploys at Locaweb, our quality did not decline. There was even a significant improvement in quality, as after the productivity increase, the number of rollbacks was reduced by 40%. This happens because with a higher frequency of deploys, the size of these deploys decreases, and consequently, since they are smaller items, the chance of errors is lower.
A simple Google search on software quality will yield tons of def- initions usually related to meeting functional and non-functional requirements. When the software does not meet a functional or non-functional requirement, it has a defect, a bug. Therefore, to improve the quality of a software product, we need to work on two things:
- Reduce existing bugs;
- Avoid generating new bugs.
A good way to control this is to have a weekly measurement of your bug inventory and new bugs, discussing it weekly with the team. We did this at Gympass. We set the goal for the bug inventory and the average of new bugs per week at the beginning of each quarter.
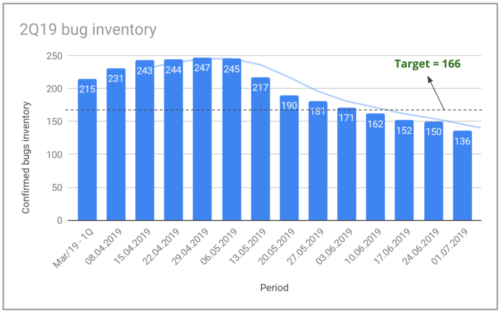 Total number of bugs at Gympass.
Total number of bugs at Gympass.
The image shows the evolution of our bug inventory for the 2nd quarter of 2019. We started the quarter with 215 bugs in our inventory and aimed for a goal of less than 166 by the end of the quarter, a reduction of almost 23%. We closed the quarter with an inventory of 136 bugs, a reduction of 36%. We achieved this by focusing not only on resolving bugs in our inventory but also on controlling the number of new bugs per week.
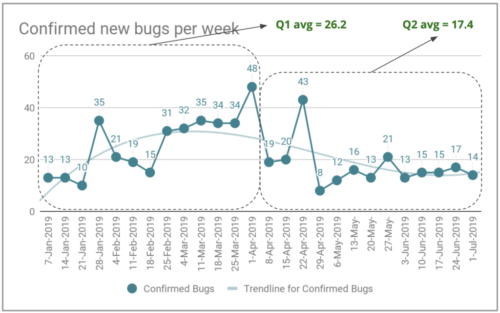 Number of new bugs detected per week at Gympass.
Number of new bugs detected per week at Gympass.
In the first quarter of 2019, we had an average of 26.2 bugs created per week. During the second quarter, we reduced this average to 17.4 new bugs per week, for a total of 226 new bugs during the quarter. This is a 33% reduction in the number of new bugs per week. This seems like a significant improvement, right? But there is still plenty of room for improvement. Let me explain the bug management math.
If we were able to reduce our bug inventory from 215 to 136, it means we resolved at least 79 bugs. However, we created 226 new bugs (17.4 new bugs per week x 13 weeks) during the quarter. We resolved 79 + 226 = 305 bugs during the quarter; that’s a lot of bug- fixing work. If we had generated 90 new bugs during the quarter, an average of 6.9 new bugs per week, instead of 226 new bugs, we could have cleared the bug inventory.
An additional aspect of bug resolution to be measured is the Service Level Agreement (SLA) for resolution, which is the number of days the team takes to resolve a bug from the day it was first identified. For this, we classified bugs by their severity, which is the impact they have on users and the business. Bugs of higher severity need to be resolved on the same day; high-severity errors in 7 days, and medium-severity errors in 14 days. The following chart shows our status at Gympass in the fourth quarter of 2019:
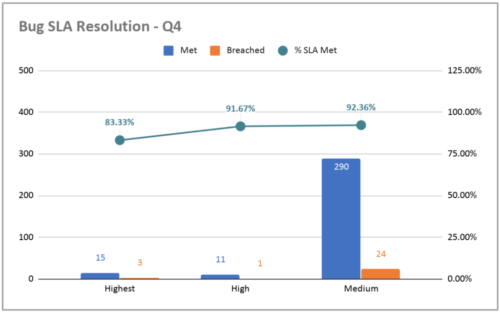 Bug resolution SLA at Gympass.
Bug resolution SLA at Gympass.
However, this is not the ideal visualization because it only shows a snapshot, not an evolution. To understand the evolution of any metric, you need to see how it performed at different points in time.
As soon as I joined Lopes, I started bringing up this topic for discussion with the teams. One thing we noticed is that 50% of the “deployed” items were bug fixes. I was told that “these bugs were caught before going into production, which is a good thing.” Indeed, it’s fortunate that these bugs didn’t reach the production environment and appear to our users. However, they did reach the pre-production stage and needed to be fixed. Wouldn’t it be better if these errors didn’t exist at all, even in pre-production?
The OKRs we defined to help us with the quality theme were 3 additional KRs in the goal to Increase the cadence of deploys in the production environment that I mentioned earlier:
- KR: Reduce the number of new bugs to 5% in pre-production;
- KR: Reduce the total number of bugs to 10% in pre-production;
- KR: Keep the total number of bugs below 5% in production.
And we added the following OKR:
- Objective: Improve the quality of squad deliveries;
- KR: Review 100% of new stories to find poorly defined and/or ambiguous requirements;
- KR: Review 25% of squad pull requests;
- KR: Measure the volume of squad pull requests.
In the first 23 days running with these OKRs at the beginning of the fourth quarter of 2021, we were able to reduce the percentage of “deployed” items for bug fixes from 52% to 31%.
Another example of bug control
At Conta Azul, we doubled the product development team in a period of 8 months between November 2017 and July 2018. This growth aimed to increase the team’s productive capacity.
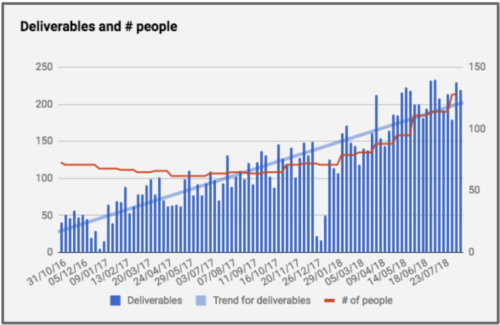 Number of deliveries and people per week from Conta Azul.
Number of deliveries and people per week from Conta Azul.
Additionally, we divided the number of deliveries by the total number of people on the team to assess if we were able to increase our individual productivity.
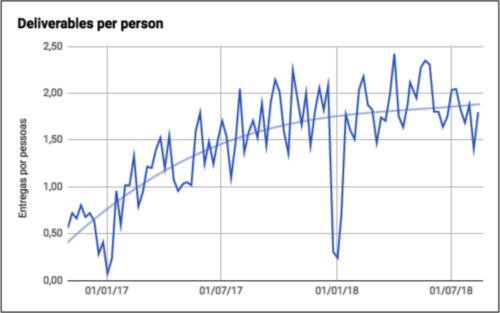 Deliveries per person per week at Conta Azul.
Deliveries per person per week at Conta Azul.
With the increase in the number of people on the team, the number of bugs also increased. The team, which already had 40% of its deliveries focused on bug fixes, saw this proportion increase to 60%. In other words, despite the increase in individual and overall productivity, this boost in productivity wasn’t translating into a better user experience, as it was being used for rework.
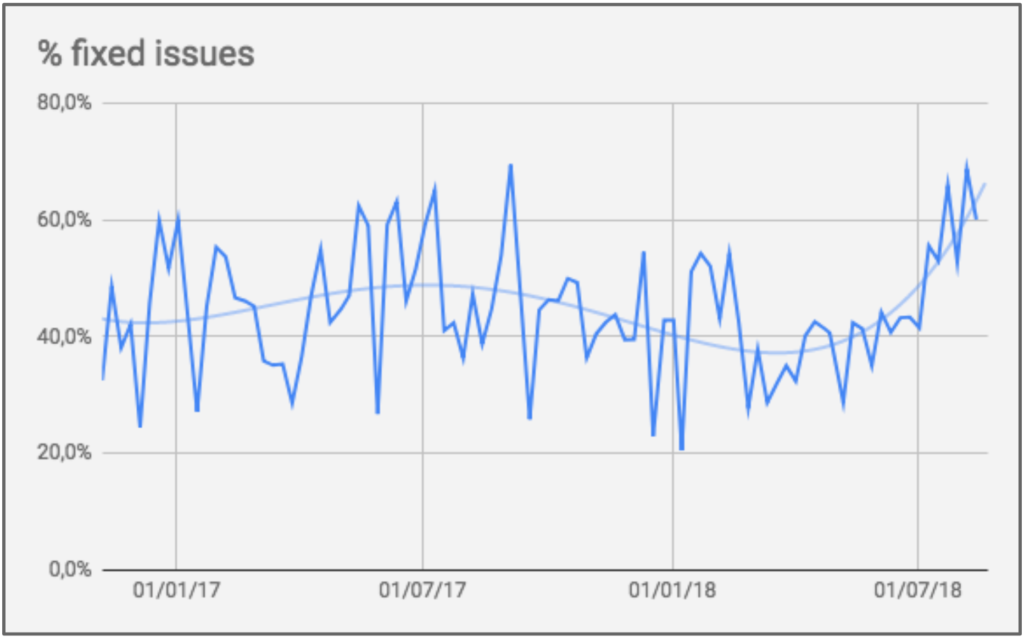 Percentage of bug fixes in Conta Azul.
Percentage of bug fixes in Conta Azul.
To control this issue, we increased our focus on fixing these bugs within the SLAs, which were:
- 85% of issues resolved within 7 days;
- 98% of issues resolved within 30 days.
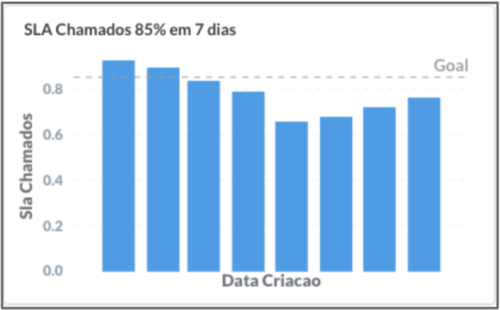 Conta Azul bug resolution SLA in 7 days.
Conta Azul bug resolution SLA in 7 days.
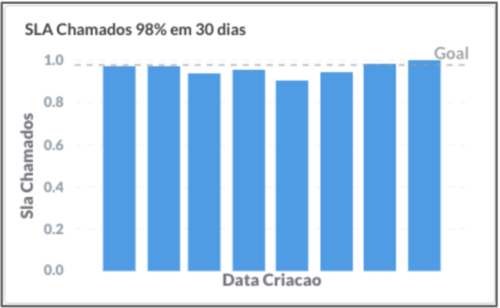 Conta Azul bug resolution SLA in 30 days.
Conta Azul bug resolution SLA in 30 days.
Note that the quality declined, and the customer suffered as a result. However, after some time, we were able to return to the defined SLA levels. We reviewed this metric weekly, and every time we discussed it, we agreed that the best way to meet the SLA was not to create bugs!
Quality is not just bug control
In addition to bug control, there are several other aspects that impact the quality of the digital product we deliver to users. Performance, scalability, operability, and monitorability are some examples of non-functional requirements.
When I joined Gympass, on my second Monday, the system went down for users around 7 PM. I started asking people on the team what was happening, and the response was that Mondays are peak days for gym visits, and sometimes the system couldn’t handle the volume. Since there was no monitoring, we were not alerted that the volume was higher than usual, and so we couldn’t prepare adequately. Two months later, when Rodrigo Rodrigues joined Gympass as CTO, he nicknamed the event “Black Mondays” due to the high volume of accesses that occurred on Mondays, similar to the high volume of accesses that e-commerce sites receive on Black Fridays. To address the problem, we started monitoring and implementing an infrastructure that could handle the peaks on Mondays. We also defined OKRs for uptime, successful HTTP requests, and backend response time.
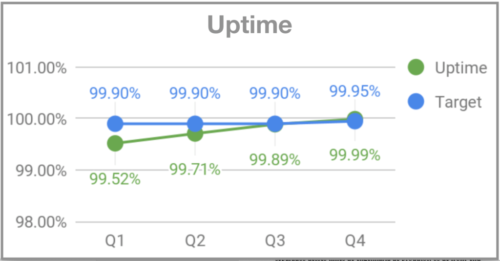 Uptime – Gympass.
Uptime – Gympass.
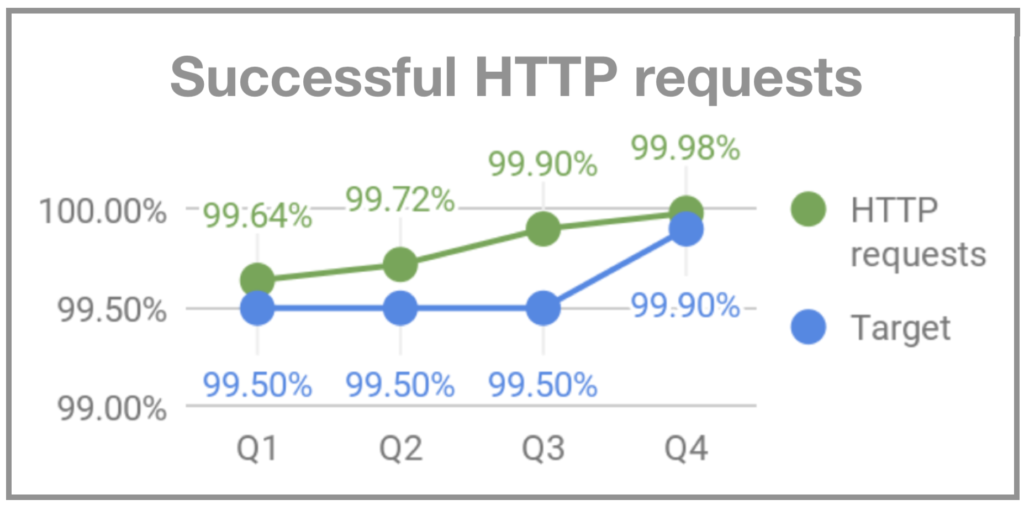 Successful HTTP requests – Gympass.
Successful HTTP requests – Gympass.
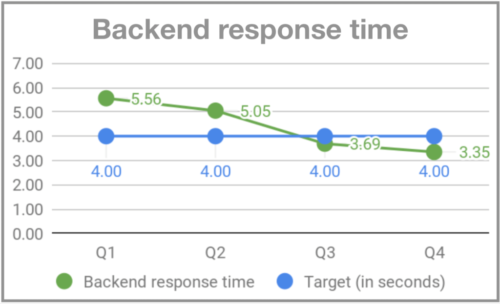 Back-end response time – Gympass.
Back-end response time – Gympass.
Why is quality so important?
Any user prefers to use a high-quality product that behaves as expected. This is a sine qua non condition for providing a good user experience.
In addition to user experience, there’s another important aspect to consider when talking about quality and bugs. Whenever someone needs to work on resolving a bug found in a digital product, that person has to stop working on whatever they were doing at that moment to address the bug. This is a disruption in the workflow. If that person were able to deliver the software without that bug, they could continue working on new things without interruptions, making them more productive.
The relationship between productivity and quality
I had the opportunity to participate in a course at MIT on creating high-velocity organizations. The course, led by Professor Steven J. Spear, author of “The High-Velocity Edge: How Market Leaders Leverage Operational Excellence to Beat the Competition,” can be summarized in one sentence:
High-velocity organizations are able to learn very quickly, especially from their failures, and absorb this learning as an integral part of the organization’s knowledge.
The concept of a high-velocity organization involves four key steps:
- Be prepared to capture knowledge and identify problems in operations;
- Understandandsolvetheseproblemstogeneratenewknowl- edge;
- Share the new knowledge across the entire organization;
- Lead to develop skills in steps 1, 2, and 3.
The classic example is Toyota, known for lean manufacturing and the practice of stopping production whenever there are issues, correcting them, and using them as learning opportunities to prevent recurrence. This ability to learn from mistakes has kept Toyota ahead of its competitors for a long time.
Another good example is Alcoa, which had a work incident rate of 2% per year, considered normal. Alcoa has more than 40,000 employees, so 2% of workplace incidents per year means that about 800 employees per year have some type of workplace incident. This is a very impressive and worrying number.
To combat this issue, they have implemented a zero-tolerance error policy. Before implementing this policy, mistakes were seen as part of the job. Now, employees are encouraged to report operating errors within 24 hours, propose solutions within 48 hours, and share the solution they found with their colleagues to ensure that knowledge spreads throughout the organization.
As a result, the risk of incidents at Alcoa dropped from 2% to 0.07% per year. This significant reduction meant that fewer than 30 employees per year experienced work-related incidents after the implementation of the zero-tolerance policy. Alcoa achieved increased productivity and quality similar to Toyota’s success by fostering a culture of continuous improvement and learning from mistakes.
Fail fast vs. learn fast
An important factor in the examples of Toyota and Alcoa is that recognizing and learning from failures should be ingrained in the company’s culture. While this is more common in the culture of technology companies, it’s not as prevalent in traditional enterprises.
During the MIT course, I shared a table with an executive from Grupo Globo, a Spanish executive from AMC Networks International (producer of series like The Walking Dead, Breaking Bad, and Mad Men), a German project manager residing in Azerbaijan working for Swire Pacific Offshore (in the oil and gas industry), and a student from Saudi Arabia pursuing a postdoc at MIT in solar energy. I was the only one from a technology company (Conta Azul at that time). The executives from Globo and AMC were there because they perceived Netflix, with its on-demand video streaming, and YouTube, with its vast catalog of user-generated videos, as major threats rapidly stealing their audience. They wanted to understand how to defend themselves, even though the topic might seem obvious for technology companies, especially with the fail-fast culture.
However, even though this is part of the culture of technology companies, sitting down and discussing it with people from more traditional companies was a great opportunity to reflect on the relationship between failure, failure recognition, learning and high speed:
- Recognizing failures and using them as a learning oppor- tunity must be well ingrained in the organization’s culture. If people are not careful, as a company grows, it can lose the ability to accept failures as learning opportunities. It is very common for companies, as they grow, to be increasingly failure-averse and create a culture that ultimately encourages people to hide mistakes and failures.
- Another important aspect of learning from failure is making this process a company standard. There is no point in failing, recognizing the error, saying that you will not make that mistake again and, some time later, making it again. This pro- cess of learning from failures must be part of the company’s culture. Whenever a failure is identified, learning must happen as quickly as possible to prevent it from happening again. If the same failure happens again, something is broken in the process of learning from the failure.
- Even in technology companies, I find that learning from failure is more common in the product development team, as retrospectives and continuous learning are part of the agile software development culture. In other areas of the company, learning from failure is less common. This ability to systematize learning from failure must permeate the entire company.
Even though we hear a lot about internet companies’ culture of failing fast, talking about failing fast diverts our focus from what’s really important: learning fast. We must put our energy into learning, not failing. It is the learning process that makes people and companies evolve. And it is the ability of an organization to learn quickly, especially from its failures, that will allow it to move at truly high speeds.
Digital transformation and product culture
This article is another excerpt from my newest book “Digital transformation and product culture: How to put technology at the center of your company’s strategy“, which I will also make available here on the blog. So far, I have already published here:
- About the book
- Part 1: Concepts
- Chapter 1: The so-called digital transformation – Project and Product
- Chapter 2: Uncertainty and digital transformation
- Chapter 3: Types of company
- Chapter 4: Type of company vs digital maturity
- Chapter 5: Business models
- Chapter 6: Agile, digital and product culture
- Part 2: Principles
- Chapter 7: Deliver early and often
Workshops, coaching, and advisory services
I’ve been helping companies and their leaders (CPOs, heads of product, CTOs, CEOs, tech founders, and heads of digital transformation) bridge the gap between business and technology through workshops, coaching, and advisory services on product management and digital transformation.
Digital Product Management Books
Do you work with digital products? Do you want to know more about managing a digital product to increase its chances of success, solve its user’s problems, and achieve the company objectives? Check out my Digital Product Management books, where I share what I learned during my 30+ years of experience in creating and managing digital products:
- Digital transformation and product culture: How to put technology at the center of your company’s strategy
- Leading Product Development: The art and science of managing product teams
- Product Management: How to increase the chances of success of your digital product
- Startup Guide: How startups and established companies can create profitable digital products
